In this article we look at embeddings with the aim of estimating the similarity between different texts. An embedding is a vector representation of a word or a text. The idea is to transform a set of words $T$ into a mathematical object $x \in \mathbb{R}^n$, with $n$ large, say a thousand or more. Crucially, the value $n$ is the same for any $T$, irrespective of the number of words that compose it; this makes it possible to compare different texts using simple vector operations.
As concrete use case, we look at the articles published on arxiv.org; the embeddings are provided by OpenAI. Our goal is to detect articles that are similar to a given one.
The requires packages are the usual suspects; the only additions are the openai and the arxiv python packages, both easily installable with pip.
import arxiv
from datetime import datetime
from IPython.display import display, HTML
import json
import matplotlib.colors as mcolors
import matplotlib.pylab as plt
import numpy as np
import pandas as pd
from pathlib import Path
import openai
from openai.embeddings_utils import cosine_similarity, get_embedding
import pickle
import requests
from sklearn.cluster import KMeans, AgglomerativeClustering
Of the many models OpenAI has published, here we are interested in text models. There are several of them, some marked as similarity and others as embedding. The difference is that similarity models tend to be used for applications where two pieces of text are compared to get a similarity score as output, while embedding models generally take an input query and then return the top $K$ best matches from a collection of texts that was embedded into a database previously. Therefore, for what we are doing here we need similarity.
models = openai.Model.list()
models = pd.DataFrame(models['data']).set_index('id')
models.created = pd.to_datetime(models.created, unit='s')
models[models.index.str.contains('text')].sort_values('created', ascending=False)[:10]
| object | created | owned_by | |
|---|---|---|---|
| id | |||
| text-embedding-ada-002 | model | 2022-12-16 19:01:39 | openai-internal |
| text-davinci-003 | model | 2022-11-28 01:40:35 | openai-internal |
| ada-code-search-text | model | 2022-04-28 19:01:50 | openai-dev |
| text-search-babbage-doc-001 | model | 2022-04-28 19:01:49 | openai-dev |
| text-search-babbage-query-001 | model | 2022-04-28 19:01:49 | openai-dev |
| text-search-curie-doc-001 | model | 2022-04-28 19:01:49 | openai-dev |
| text-search-curie-query-001 | model | 2022-04-28 19:01:49 | openai-dev |
| babbage-code-search-text | model | 2022-04-28 19:01:49 | openai-dev |
| code-search-babbage-text-001 | model | 2022-04-28 19:01:47 | openai-dev |
| code-search-ada-text-001 | model | 2022-04-28 19:01:47 | openai-dev |
OpenAI suggests to use text-embedding-ada-002, so this is what we will use.
According to OpenAI, this new model unifies the specific models for text similarity, text search and code search into a single new model, and performs better than the previous embedding models across a diverse set of text search, sentence similarity, and code search benchmarks. The price at the time of writing is about 3,000 pages per dollar, which is quite cheap. An alternative would be text-similarity-ada-001, not displayed in the list above because released in April 2022.
Since our scope is to search for similar articles published on arxiv.org, we first need to download the salient features of the articles. We will limit ourselve to title and summary, although a deeper analysis would also focus on the article content (which needs extracing from the PDF or from the source files). The nice arxiv package provides an easy-to-use API for doing exactly that. The query() function below simply queries for the specified number of articles, sortd by update date, and returns a list with the provided metadata.
def query(query, max_results, offset: int = 0):
search = arxiv.Search(
query=query,
max_results=max_results,
sort_by=arxiv.SortCriterion.LastUpdatedDate
)
client = arxiv.Client()
return list(client.results(search=search, offset=offset))
As a first check, we query the last 50 articles in six categories that are quite different from each other: astrophysics, economics, condensed matter, quantitative biology and quantitative finance. In general an article on astrophysics should have little in common with one on quantitative finance or condensed matter. Overlaps may exists between economics and quantitative finance, and mathematics is used in all other sciences. To make things a bit more difficult, arxiv has a single main category as well as many secondary ones, and the query for a certain category returns articles that have that category as either the main or one of the secondary ones, so the distinction may not always be clear-cut. All considered, though, we should be able to cluster them quite nicely
results = []
for cat in ['astro-ph', 'econ', 'cond-mat', 'math', 'q-bio', 'q-fin']:
results += query(f'cat:{cat}.*', 50, offset=0)
We use title and summary to compute the embedding. It takes about a minute to call get_embedding() for the 300 articles of our tests; once computed, embeddings are stored in a dataframe together with the title. The embedding is defined as the title plus the summary.
def get_text(result):
return result.title + ' ' + result.summary.replace('\n', ' ')
embeddings = []
for result in results:
embeddings.append(get_embedding(get_text(result), "text-embedding-ada-002"))
def assemble_df(results, embeddings):
assert len(results) == len(embeddings)
get_main_cat = lambda x: x if '.' not in x else x[:x.find('.')]
return pd.DataFrame({
'embedding': embeddings,
'title': [r.title for r in results],
'summary': [r.summary for r in results],
'date': [r.published for r in results],
'entry_id': [r.entry_id for r in results],
'primary_category': [get_main_cat(r.primary_category) for r in results],
'categories': [[get_main_cat(c) for c in r.categories] for r in results]
})
df = assemble_df(results, embeddings)
The embeddings have a dimension of 1536.
print(f"# dimensions: {len(df.embedding.values[0])}")
# dimensions: 1536
As we expect six clusters we choose num_clusters=6. As suggested by OpenAI, we use K-means clustering and t-SNE for reducing the dimensionality to two, making visualizations possible.
matrix = np.vstack(df.embedding.values)
num_clusters = 6
kmeans = KMeans(n_clusters=num_clusters, init="k-means++", random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df["cluster"] = labels
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8, 8))
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]
labels = {}
for cluster in range(6):
subset = df[df.cluster == cluster]
freq = pd.Series(subset.primary_category.tolist()).value_counts()
labels[cluster] = f'#{cluster}' + ', '.join([f' {cat} ({count})' for cat, count in freq[:4].items()])
labels
for cluster, color in enumerate(['tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown']):
xs = np.array(x)[df.cluster == cluster]
ys = np.array(y)[df.cluster == cluster]
plt.scatter(xs, ys, color=color, alpha=0.4, label=labels[cluster])
plt.scatter(xs.mean(), ys.mean(), marker="s", color=color, s=150)
plt.title("2D t-SNE Clusters")
fig.tight_layout()
plt.legend();
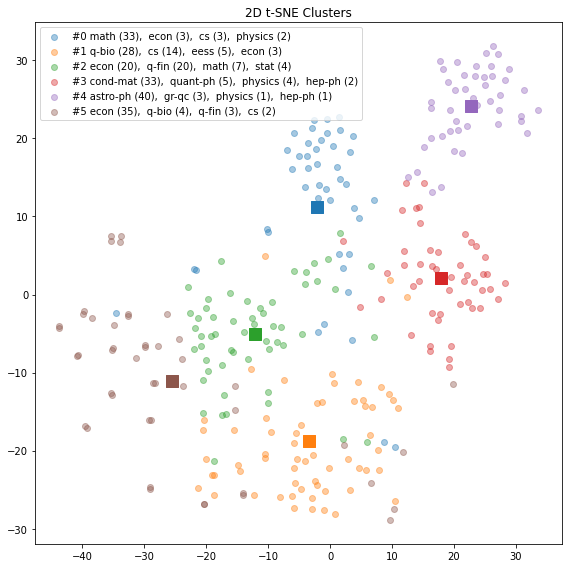
Results aren quite good, with cluster #0 (mathematics), cluster #3 (condensed matter) and cluster #4 (astrophysics) quite distinct. Cluster #1 (quantitative biology) is a bit dispersed over other clusters, while clusters #2 and #5 have some overlap.
We are now ready to apply the method on articles for which we don’t know the answer: here we take all the articles in the quantitative finance category with the word volatility in the title. This covers about 950 articles published from 1997 to 2023.
results = query("cat:q-fin.* AND ti:volatility", None)
print(f"Found {len(results)} results.")
Found 947 results.
The five most recent ones are the following:
def to_html(results):
text = "<table><tr><th>Publication Date</th><th></th><th style='text-align:left'>Authors and Title</th></tr>"
for r in results:
authors = ', '.join(a.name for a in r.authors)
categories = ', '.join(r.categories)
text += f"<tr><td width=100>{datetime.strftime(r.published, '%Y-%m-%d')}</td>" \
+ f"<td width=20><a style='text-decoration: none;' href='{r.entry_id}'>🔗</a></td>" \
+ f"<td style='text-align:left'><tt>{categories}</tt><br>{authors}<br><b>{r.title}</b></td></tr>"
text += "</table>"
display(HTML(text))
to_html(results[0:5])
| Publication Date | Authors and Title | |
|---|---|---|
| 2022-04-21 | 🔗 | q-fin.MF, math.PR, 91G20, 60H30, 60F10, 60G22 Giacomo Giorgio, Barbara Pacchiarotti, Paolo Pigato Short-time asymptotics for non self-similar stochastic volatility models |
| 2023-11-08 | 🔗 | q-fin.ST, q-fin.MF, q-fin.TR Siu Hin Tang, Mathieu Rosenbaum, Chao Zhou Forecasting Volatility with Machine Learning and Rough Volatility: Example from the Crypto-Winter |
| 2021-12-09 | 🔗 | q-fin.CP, econ.EM Zhe Wang, Nicolas Privault, Claude Guet Deep self-consistent learning of local volatility |
| 2023-07-27 | 🔗 | q-fin.ST, q-fin.PR, q-fin.RM Darsh Kachhara, John K. E Markin, Astha Singh Option Smile Volatility and Implied Probabilities: Implications of Concavity in IV Curves |
| 2023-11-02 | 🔗 | q-fin.MF, math.PR, 91G30, 60H10, 60H35, 60G22 Giulia Di Nunno, Anton Yurchenko-Tytarenko Power law in Sandwiched Volterra Volatility model |
As done before, we compute the embeddings using title and summary.
embeddings = []
for result in results:
embeddings.append(get_embedding(get_text(result), "text-embedding-ada-002"))
import pickle
with open('data.pickle', 'wb') as f:
pickle.dump((results, embeddings), f)
import pickle
with open('data.pickle', 'rb') as f:
results, embeddings = pickle.load(f)
df = assemble_df(results, embeddings)
matrix = np.vstack(df.embedding.values)
Since we don’t know how many clusters we have, we use the agglomerative clustering method.
ac = AgglomerativeClustering(n_clusters=None, distance_threshold=1.5)
ac.fit(matrix)
labels = ac.labels_
df["cluster"] = labels
num_clusters = ac.n_clusters_
Instead of the t-SNE visualization, which will add little to our case, we use gpt-4 to obtain a list of keywords that describe the clusters. We do that by collecting all the titles, without the summaries to make the request shorter, for each cluster and calling openai.ChatCompletion.create().
def get_completion(prompt, model="gpt-3.5-turbo-16k", temperature=0):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature,
)
return response.usage.total_tokens, response.choices[0].message["content"]
topics = {}
for cluster in range(num_clusters):
titles = '\n\n'.join([t for t in df[df.cluster == cluster].title])
prompt = f"""
You are an expert in quantitative finance and you are helping reviewing the
titles of scientific articles.
What are the 5 most important topics of the following titles of scientific articles.
Return the answers as json that contains all the topics in a list under the tag "topics".
{titles}"""
_, response = get_completion(prompt)
topics[cluster] = json.loads(response)['topics']
We report the topics as suggested by the LLM together with a few titles of the articles in the cluster.
html = "<table>"
for cluster, topic in topics.items():
t = f'#{cluster} ' + ', '.join(topic)
articles = '<li>'.join([row.title for _, row in df[df.cluster == cluster][:10].iterrows()])
html += f"<tr><td><b>{t} </b><ul><li>{articles} </ul></td></tr>"
html += "</table>"
display(HTML(html))
Cluster 0: Cryptocurrency market dynamics, Stock market volatility, GDP prediction, Monetary policy announcements, European carbon and energy prices
- Bayesian framework for characterizing cryptocurrency market dynamics, structural dependency, and volatility using potential field
- The Effect of COVID-19 on Cryptocurrencies and the Stock Market Volatility – A Two-Stage DCC-EGARCH Model Analysis
- Harnessing the Potential of Volatility: Advancing GDP Prediction
- Volatility jumps and the classification of monetary policy announcements
- Modeling Volatility and Dependence of European Carbon and Energy Prices
- Nowcasting Stock Implied Volatility with Twitter
- Ask “Who”, Not “What”: Bitcoin Volatility Forecasting with Twitter Data
- Role of Variable Renewable Energy Penetration on Electricity Price and its Volatility Across - Independent System Operators in the United States
- Investor base and idiosyncratic volatility of cryptocurrencies
- FX Resilience around the World: Fighting Volatile Cross-Border Capital Flows
Cluster 1: Stochastic volatility models, Rough volatility, Option pricing, Volatility estimation, Model calibration
- Short-time asymptotics for non self-similar stochastic volatility models
- Power law in Sandwiched Volterra Volatility model
- From constant to rough: A survey of continuous volatility modeling
- Thiele’s PIDE for unit-linked policies in the Heston-Hawkes stochastic volatility model
- Instabilities of Super-Time-Stepping Methods on the Heston Stochastic Volatility Model
- Convergence of the Euler–Maruyama particle scheme for a regularised McKean–Vlasov equation arising from the calibration of local-stochastic volatility models
- A stochastic volatility model for the valuation of temperature derivatives
- Estimating the roughness exponent of stochastic volatility from discrete observations of the realized variance
- A lower bound for the volatility swap in the lognormal SABR model
- Statistical inference for rough volatility: Central limit theorems
Cluster 2: Return and Volatility Modeling, Algorithmic Trading, News-driven Expectations, Bitcoin Volatility, Volatility Models
- A Modeling Approach of Return and Volatility of Structured Investment Products with Caps and Floors
- Sizing Strategies for Algorithmic Trading in Volatile Markets: A Study of Backtesting and Risk Mitigation Analysis
- News-driven Expectations and Volatility Clustering
- Bitcoin Volatility and Intrinsic Time Using Double Subordinated Levy Processes
- Spatial and Spatiotemporal Volatility Models: A Review
- VolTS: A Volatility-based Trading System to forecast Stock Markets Trend using Statistics and Machine Learning
- Liquidity Premium, Liquidity-Adjusted Return and Volatility, and a Unified Modern Portfolio Theory: illustrated with Crypto Assets
- Systemic risk indicator based on implied and realized volatility
- On the Guyon-Lekeufack Volatility Model
- Dynamic Risk Measurement by EVT based on Stochastic Volatility models via MCMC
Cluster 3: Asian Options, Implied Volatility, Stochastic Volatility Models, Option Pricing, Local Volatility Models
- Asymptotics for Short Maturity Asian Options in a Jump-Diffusion model with Local Volatility
- On the implied volatility of European and Asian call options under the stochastic volatility Bachelier model
- On the implied volatility of Asian options under stochastic volatility models
- Dark Matter in (Volatility and) Equity Option Risk Premiums
- Approximate Pricing of Derivatives Under Fractional Stochastic Volatility Model
- Option Pricing with Time-Varying Volatility Risk Aversion
- Hull and White and Alòs type formulas for barrier options in stochastic volatility models with nonzero correlation
- Pricing Path-dependent Options under Stochastic Volatility via Mellin Transform
- Optimal market completion through financial derivatives with applications to volatility risk
- Toward an efficient hybrid method for pricing barrier options on assets with stochastic volatility
Cluster 4: Option pricing, Implied volatility, Volatility smile, Stochastic volatility models, Arbitrage-free models
- Option Smile Volatility and Implied Probabilities: Implications of Concavity in IV Curves
- On the skew and curvature of implied and local volatilities
- Building arbitrage-free implied volatility: Sinkhorn’s algorithm and variant
- Extreme ATM skew in a local volatility model with discontinuity: joint density approach
- The quintic Ornstein-Uhlenbeck volatility model that jointly calibrates SPX and VIX smiles
- Sparse modeling approach to the arbitrage-free interpolation of plain-vanilla option prices and implied volatilities
- Adaptive Gradient Descent Methods for Computing Implied Volatility
- Tighter ‘Uniform Bounds for Black-Scholes Implied Volatility’ and the applications to root-finding
- Joint SPX-VIX calibration with Gaussian polynomial volatility models: deep pricing with quantization
- Reconstructing Volatility: Pricing of Index Options under Rough Volatility
luster 5: Volatility forecasting, Machine learning, Deep learning, Neural networks, Financial time series
- Forecasting Volatility with Machine Learning and Rough Volatility: Example from the Crypto-Winter
- Co-Training Realized Volatility Prediction Model with Neural Distributional Transformation
- DeepVol: A Pre-Trained Universal Asset Volatility Model
- Combining Deep Learning and GARCH Models for Financial Volatility and Risk Forecasting
- Stock Volatility Prediction Based on Transformer Model Using Mixed-Frequency Data
- Introducing the σ-Cell: Unifying GARCH, Stochastic Fluctuations and Evolving Mechanisms in RNN-based Volatility Forecasting
- Recurrent Neural Networks with more flexible memory: better predictions than rough volatility
- Graph Neural Networks for Forecasting Multivariate Realized Volatility with Spillover Effects
- Comparing Deep Learning Models for the Task of Volatility Prediction Using Multivariate Data
- Short-Term Volatility Prediction Using Deep CNNs Trained on Order Flow
Cluster 6: Deep learning, Calibration, Local volatility models, Stochastic volatility models, Implied volatility surfaces
- Deep self-consistent learning of local volatility
- No-Arbitrage Deep Calibration for Volatility Smile and Skewness
- Approximation Rates for Deep Calibration of (Rough) Stochastic Volatility Models
- Applying Deep Learning to Calibrate Stochastic Volatility Models
- Joint Calibration of Local Volatility Models with Stochastic Interest Rates using Semimartingale Optimal Transport
- A new encoding of implied volatility surfaces for their synthetic generation
- Calibrating Local Volatility Models with Stochastic Drift and Diffusion
- Random neural networks for rough volatility
- Calibration of Local Volatility Models with Stochastic Interest Rates using Optimal Transport
- Learning Volatility Surfaces using Generative Adversarial Networks
Cluster 7: Optimal portfolios, Stochastic volatility, Stackelberg game, Robust replication, Hedging
- Analysis of optimal portfolios on finite and small-time horizons for a multi-dimensional correlated stochastic volatility model
- A Stackelberg reinsurance-investment game under α-maxmin mean-variance criterion and stochastic volatility
- Ergodic robust maximization of asymptotic growth under stochastic volatility
- Optimal Investment with Correlated Stochastic Volatility Factors
- CVA in fractional and rough volatility models
- Safe Delivery of Critical Services in Areas with Volatile Security Situation via a Stackelberg Game Approach
- Can Volatility Solve the Naive Portfolio Puzzle?
- Robust replication of barrier-style claims on price and volatility
- Pricing Interest Rate Derivatives under Volatility Uncertainty
- Term Structure Modeling under Volatility Uncertainty
The work ‘volatility’ is in all clusters, but this shouldn’t surprise given that we have selected the articles that contain it in the title! Five clusters reference ‘stochastic volatility’, although from different angles: cluster 1 from a modeling perspective (the SDE formulation), cluster 3 applied to option pricing, cluster 4 refers more to the smile representation, cluster 6 points to papers applying machine learning and option pricing, and cluster 7 refers to portfolio theory and portfolio selection. The distinction isn’t always clear, suggesting that the clustering algorithm could be improved or fine-tuned.
Another possible application is to search for articles that are similar to a selected on. We choose the paper Variational Autoencoders: A Hands-Off Approach to Volatility and try to find similar ones, using cosine similarity.
selected_title = 'Variational Autoencoders: A Hands-Off Approach to Volatility'
selected_id = df.index[df.title == selected_title].values[0]
print(f'Cluster: {df.loc[selected_id].cluster}\nTitle: {df.loc[selected_id].title}\nSummary: {df.loc[selected_id].summary}')
Cluster: 6
Title: Variational Autoencoders: A Hands-Off Approach to Volatility
Summary: A volatility surface is an important tool for pricing and hedging
derivatives. The surface shows the volatility that is implied by the market
price of an option on an asset as a function of the option's strike price and
maturity. Often, market data is incomplete and it is necessary to estimate
missing points on partially observed surfaces. In this paper, we show how
variational autoencoders can be used for this task. The first step is to derive
latent variables that can be used to construct synthetic volatility surfaces
that are indistinguishable from those observed historically. The second step is
to determine the synthetic surface generated by our latent variables that fits
available data as closely as possible. As a dividend of our first step, the
synthetic surfaces produced can also be used in stress testing, in market
simulators for developing quantitative investment strategies, and for the
valuation of exotic options. We illustrate our procedure and demonstrate its
power using foreign exchange market data.
selected = df.loc[selected_id].embedding
df['similarity'] = df.embedding.apply(lambda x: cosine_similarity(x, selected))
for i, row in df.sort_values('similarity', ascending=False)[:20].iterrows():
if i == selected_id:
continue
print(f"{str(row.date)[:10]} {row.entry_id} (#{row.cluster}, simil={row.similarity:.3f}) {row.title}")
2022-11-23 http://arxiv.org/abs/2211.12892v2 (#6, simil=0.920) A new encoding of implied volatility surfaces for their synthetic generation
2021-08-10 http://arxiv.org/abs/2108.04941v3 (#6, simil=0.912) Arbitrage-Free Implied Volatility Surface Generation with Variational Autoencoders
2021-06-14 http://arxiv.org/abs/2106.07177v2 (#6, simil=0.904) A Two-Step Framework for Arbitrage-Free Prediction of the Implied Volatility Surface
2020-05-05 http://arxiv.org/abs/2005.02505v3 (#6, simil=0.888) A generative adversarial network approach to calibration of local stochastic volatility models
2023-04-25 http://arxiv.org/abs/2304.13128v1 (#6, simil=0.884) Learning Volatility Surfaces using Generative Adversarial Networks
2020-07-20 http://arxiv.org/abs/2007.10462v1 (#6, simil=0.884) Deep Local Volatility
2017-10-02 http://arxiv.org/abs/1710.00859v1 (#2, simil=0.883) Managing Volatility Risk: An Application of Karhunen-Loève Decomposition and Filtered Historical Simulation
2023-03-01 http://arxiv.org/abs/2303.00859v3 (#6, simil=0.881) FuNVol: A Multi-Asset Implied Volatility Market Simulator using Functional Principal Components and Neural SDEs
2019-09-21 http://arxiv.org/abs/1909.11009v1 (#0, simil=0.880) Implied volatility surface predictability: the case of commodity markets
2023-05-06 http://arxiv.org/abs/2305.04137v1 (#2, simil=0.879) Volatility of Volatility and Leverage Effect from Options
2022-09-22 http://arxiv.org/abs/2209.10771v2 (#5, simil=0.879) Physics-Informed Convolutional Transformer for Predicting Volatility Surface
2009-05-20 http://arxiv.org/abs/0905.3326v1 (#1, simil=0.876) Volatility derivatives in market models with jumps
2021-12-09 http://arxiv.org/abs/2201.07880v2 (#6, simil=0.876) Deep self-consistent learning of local volatility
2016-02-13 http://arxiv.org/abs/1602.04372v1 (#6, simil=0.875) Local Volatility Models in Commodity Markets and Online Calibration
2022-04-11 http://arxiv.org/abs/2204.05806v1 (#5, simil=0.875) Variational Heteroscedastic Volatility Model
2022-12-20 http://arxiv.org/abs/2212.09957v1 (#6, simil=0.874) Beyond Surrogate Modeling: Learning the Local Volatility Via Shape Constraints
2019-01-17 http://arxiv.org/abs/1901.06021v2 (#6, simil=0.874) A Probabilistic Approach to Nonparametric Local Volatility
2019-04-29 http://arxiv.org/abs/1904.12834v5 (#6, simil=0.873) Incorporating prior financial domain knowledge into neural networks for implied volatility surface prediction
2022-04-14 http://arxiv.org/abs/2204.06943v2 (#3, simil=0.873) Option Pricing with Time-Varying Volatility Risk Aversion
The similarity level is always quite high, above 0.87, suggesting that perhaps the texts above are all quite similar in general terms, so similarity alone may not suffice. Still, we manage to find relevant articles, as one could see by looking at the references in the one we have selected or in the list of articles that cite it or by the publications of the authors. The most similar papers are all in cluster #6, the one for machine learning applications.
To conclude, the results are quite satisfactory given the limited effort. We have only used the article title and abstract; references, citations and authors are easily available and in a real-life applications we would surely use them to increase the precision of the suggestions. A further extension would be to extract the text from the article.