[Updated on August 2023 to use gymnasium instead of gym.]
In this post we will show some basic configurations and commands for the Atari environments provided by the Farama Gymnasium. These environments are based on the Arcade Learning Environment, or ALE, a project that provides the interfaces to hundreds of Atari 2600 games. The idea is to have cool and interesting problems to solve, and get nice visualizations, too. More than five hundred games were produced for this console, which was quite popular for about a decade after being released in 1977; the production of the 2600 series ended in 1992. The games are quite simple by today’s standard, both in the graphics but also in the controls. They are also typically quick to play, and hence not too difficult to understand and learn. The original CPU ran at 1.19 MHz (yes, mega, not giga) and it can be emulated faster than real-time on modern hardware. Even more interesting for today’s standard, the console had 128 bytes of RAM for scratch space, the call stack, and the state of the game environment.
The environment is created using Python 3.10 and the following packages:
python -m venv atari
./atari/Scripts/activate
pip install ipywidgets ipykernel matplotlib nbconvert numpy
pip install gymnasium[atari]
pip install gymnasium[accept-rom-license]
pip install gymnasium[other]
import gymnasium as gym
import matplotlib.pylab as plt
import numpy as np
from PIL import Image, ImageDraw, ImageFont
After importing the ROMS we should have a bit less than 900 environments.
env_ids = list(gym.envs.registry.keys())
print(f"Found {len(env_ids)} environments")
Found 1003 environments
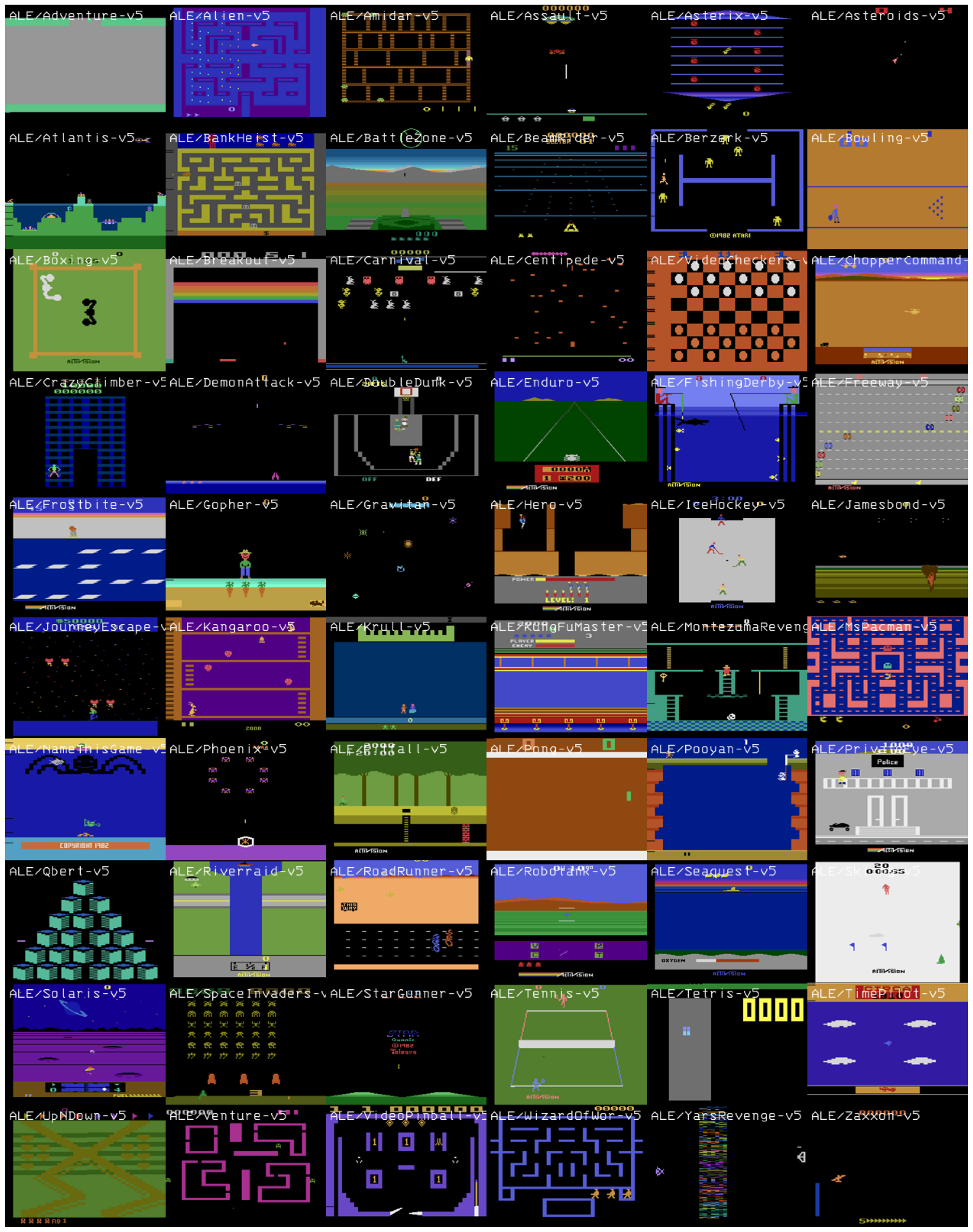
What we do next is to manually select 60 environments for which we can generate a nice image. The latest version is v5 and is identified by the ALE/ prefix.
selected_env_ids = [
'ALE/Adventure-v5',
'ALE/Alien-v5',
'ALE/Amidar-v5',
'ALE/Assault-v5',
'ALE/Asterix-v5',
'ALE/Asteroids-v5',
'ALE/Atlantis-v5',
'ALE/BankHeist-v5',
'ALE/BattleZone-v5',
'ALE/BeamRider-v5',
'ALE/Berzerk-v5',
'ALE/Bowling-v5',
'ALE/Boxing-v5',
'ALE/Breakout-v5',
'ALE/Carnival-v5',
'ALE/Centipede-v5',
'ALE/VideoCheckers-v5',
'ALE/ChopperCommand-v5',
'ALE/CrazyClimber-v5',
'ALE/DemonAttack-v5',
'ALE/DoubleDunk-v5',
'ALE/Enduro-v5',
'ALE/FishingDerby-v5',
'ALE/Freeway-v5',
'ALE/Frostbite-v5',
'ALE/Gopher-v5',
'ALE/Gravitar-v5',
'ALE/Hero-v5',
'ALE/IceHockey-v5',
'ALE/Jamesbond-v5',
'ALE/JourneyEscape-v5',
'ALE/Kangaroo-v5',
'ALE/Krull-v5',
'ALE/KungFuMaster-v5',
'ALE/MontezumaRevenge-v5',
'ALE/MsPacman-v5',
'ALE/NameThisGame-v5',
'ALE/Phoenix-v5',
'ALE/Pitfall-v5',
'ALE/Pong-v5',
'ALE/Pooyan-v5',
'ALE/PrivateEye-v5',
'ALE/Qbert-v5',
'ALE/Riverraid-v5',
'ALE/RoadRunner-v5',
'ALE/Robotank-v5',
'ALE/Seaquest-v5',
'ALE/Skiing-v5',
'ALE/Solaris-v5',
'ALE/SpaceInvaders-v5',
'ALE/StarGunner-v5',
'ALE/Tennis-v5',
'ALE/Tetris-v5',
'ALE/TimePilot-v5',
'ALE/UpNDown-v5',
'ALE/Venture-v5',
'ALE/VideoPinball-v5',
'ALE/WizardOfWor-v5',
'ALE/YarsRevenge-v5',
'ALE/Zaxxon-v5']
def get_image(env_id):
try:
env = gym.make(env_id)
obs = env.reset()
for _ in range(10):
obs, _, terminated, truncated, _ = env.step(env.action_space.sample())
if terminated or truncated:
break
env.close()
except Exception as e:
print(e)
obs = None
return obs
images = {}
for env_id in selected_env_ids:
image = get_image(env_id)
if image is not None:
images[env_id] = image
Not all the images have the same resolution, yet most of them are 210 pixels times 160 pixels. We reshape those that aren’t to be 210x160.
width, height = 210, 160
resized = []
font = ImageFont.truetype("font3270.otf", 20)
for env_id, image in images.items():
image = Image.fromarray(image)
image = image.resize((width, height))
draw = ImageDraw.Draw(image)
draw.text((5,5), env_id, font=font)
image = np.array(image)
resized.append(image)
resized = np.array(resized)
resized = resized.reshape(10, 6, height, width, 3)
final = np.vstack([np.hstack(row) for row in resized])
plt.figure(figsize=(24, 200))
plt.imshow(final)
plt.axis('off');
We now take one famous game, ‘Breakout`, and we play using a random strategy. In a subsequent article we’ll see how to use more sophisticated methods, but for the moment we content ourselves with a nice visualization.
from gymnasium import Wrapper
from gymnasium.wrappers import FrameStack, GrayScaleObservation, ResizeObservation
class Recorder(Wrapper):
history = []
def __init__(self, env):
super().__init__(env)
def step(self, action):
obs, reward, terminated, truncated, info = super().step(action)
self.history.append((action, obs, reward, terminated, truncated, info))
return obs, reward, terminated, truncated, info
def reset(self, **kwargs):
retval = super().reset(**kwargs)
self.history.clear()
return retval
def close(self):
return super().close()
@classmethod
def get_actions(cls):
return list(map(lambda x: x[0], cls.history))
@classmethod
def get_observations(cls):
return list(map(lambda x: x[1], cls.history))
@classmethod
def get_rewards(cls):
return list(map(lambda x: x[2], cls.history))
env = gym.make("ALE/Breakout-v5")
env = Recorder(env)
For this game we have four discrete actions, as we can see with the command env.unwrapped.get_action_meanings(). The actions are NOOP, FIRE, RIGHT, LEFT.
action_meanings = env.unwrapped.get_action_meanings()
We play one thousand games using a random strategy (that is, the action at each step is randomly chosen among the valid ones) and select the best one, for which we generate the video. Interestingly, sometimes we score a few points, even if we are basically playing without any strategy! Looking at the video, it even seems that the agent is playing with some strategy, or trying to get the ball – it looks a bit intellingent while in reality it isn’t.
env.action_space.seed(42)
env.reset(seed=43)
best_total_reward = -np.inf
for game in range(1_000):
obs, info = env.reset()
step, total_reward = 0, 0.0
while True:
obs, reward, terminated, truncated, info = env.step(action=env.action_space.sample())
total_reward += reward
if terminated or truncated:
break
step += 1
if total_reward > best_total_reward:
print(f'game {game}: # steps: {step}, total reward: {total_reward}')
# np array with shape (frames, height, width, channels)
video = np.array(Recorder.get_observations())
actions = list(map(lambda i: action_meanings[i], Recorder.get_actions()))
rewards = Recorder.get_rewards()
best_total_reward = total_reward
game 0: # steps: 159, total reward: 1.0
game 1: # steps: 201, total reward: 2.0
game 5: # steps: 250, total reward: 3.0
game 11: # steps: 328, total reward: 4.0
game 28: # steps: 315, total reward: 5.0
game 166: # steps: 359, total reward: 6.0
i = 10
f"Action: {actions[i]}, reward: {rewards[i]}"
'Action: RIGHT, reward: 0.0'
from matplotlib import animation
from IPython.display import HTML
fig, ax = plt.subplots(figsize=(8, 10))
im = plt.imshow(video[0,:,:,:])
txt = plt.text(10, 25, '', color='red')
plt.axis('off')
plt.close() # this is required to not display the generated image
def init():
im.set_data(video[0,:,:,:])
def animate(i):
im.set_data(video[i,:,:,:])
txt.set_text(f"Action: {actions[i]}, reward: {rewards[i]}")
return im
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=video.shape[0],
interval=50)
anim.save('./atari-video.gif', writer='Pillow', fps=10)
WARNING:matplotlib.animation:MovieWriter Pillow unavailable; using Pillow instead.