In this article we focus on the Street View House Numbers dataset. It contains real-world image obtained from house numbers in Google Street View images. We will use it to check the effectiveness of weight averaging for neural networks on a simple, small convolutional neural network.
import matplotlib.pylab as plt
plt.style.use('ggplot')
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from copy import deepcopy
from tqdm import tqdm
trainset = torchvision.datasets.SVHN(root='./data', split='train', transform=transforms.ToTensor(), download=True)
This problem is much more difficult than MNIST due to the lack of contrast normalisation, overlapping digits, and distracting features, as we can see in the samples below.
fig, axes = plt.subplots(figsize=(8, 8), nrows=4, ncols=4)
for i, ax in enumerate(axes.ravel()):
ax.imshow(trainset.data[i * 100].transpose((1, 2, 0)))
ax.set_title(trainset.labels[i * 100])
ax.axis('off')
fig.tight_layout()

transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.SVHN(
root='./data',
split='train',
download=True,
transform=transform
)
testset = torchvision.datasets.SVHN(
root='./data',
split='test',
download=True,
transform=transform
)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=256, shuffle=False)
print(f"Train dataset contains {len(trainset):,} images; test dataset contains {len(testset):,}.")
Train dataset contains 73,257 images; test dataset contains 26,032.
We use a simple CNN model.
class SmallCNN(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 16 * 16, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.features(x)
return self.classifier(x)
def get_device():
if torch.cuda.is_available():
return "cuda"
if torch.mps.is_available():
return "mps"
return "cpu"
The main idea of weight averaging is to keep track of the model weights across epochs and average them to define a new model. Generally we let a few epochs go before start (in this case 10) and record the following weights till the last epoch (here 20).
def train_and_collect_checkpoints(num_epochs, min_epoch):
device = get_device()
model = SmallCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.05, momentum=0.9)
checkpoints = []
for epoch in tqdm(range(num_epochs)):
model.train()
for x, y in trainloader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
out = model(x)
loss = criterion(out, y)
loss.backward()
optimizer.step()
if epoch >= min_epoch:
checkpoints.append(deepcopy(model.state_dict()))
return checkpoints
def average_checkpoints(checkpoints):
avg_state = deepcopy(checkpoints[0])
for key in avg_state.keys():
for i in range(1, len(checkpoints)):
avg_state[key] += checkpoints[i][key]
avg_state[key] /= len(checkpoints)
averaged_model = SmallCNN()
averaged_model.load_state_dict(avg_state)
return averaged_model
def accuracy(model):
device = next(model.parameters()).device
model.eval()
total = 0
correct = 0
with torch.no_grad():
for x, y in testloader:
x, y = x.to(device), y.to(device)
out = model(x)
_, preds = out.max(1)
total += y.size(0)
correct += preds.eq(y).sum().item()
return 100 * correct / total
checkpoints = train_and_collect_checkpoints(20, 10)
100%|██████████| 20/20 [02:51<00:00, 8.59s/it]
individual_accs = []
for ckpt in checkpoints:
m = SmallCNN()
m.load_state_dict(ckpt)
acc = accuracy(m)
individual_accs.append(acc)
avg_model = average_checkpoints(checkpoints)
avg_acc = accuracy(avg_model)
plt.plot(individual_accs, 'o-', label='Epochs')
plt.axhline(y=avg_acc, color='coral', linestyle='dashed', label='Averaged model')
plt.axhline(y=sum(individual_accs) / len(individual_accs), linestyle='-.', color='grey', label='Mean accuracy of checkpoints')
plt.legend()
plt.xlabel('Checkpoints')
plt.ylabel('Accuracy (%)');
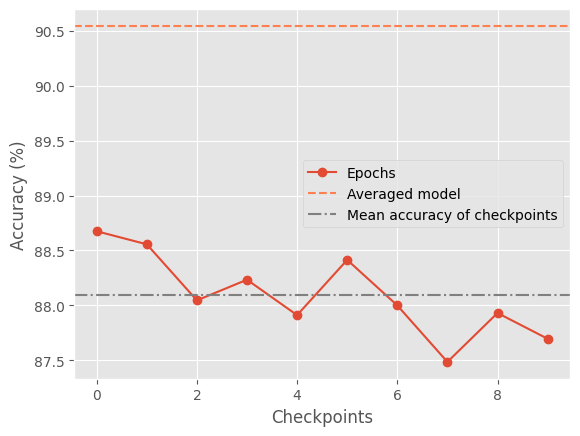
SVHN tends to produce visible oscillations in later SGD epochs, so averaging stabilizes the solution and improves generalization – here we see a 1%/2% improvement in the accuracy.