In this article we look at another classical problem, the car racing one.
The notebook can be run on an Ubuntu computer with the following conda environment:
conda create --name car-racing python==3.7 --no-default-packages -y
conda activate car-racing
sudo apt-get install xvfb
sudo apt-get install freeglut3-dev
pip install gym[box2d] torch jupyterlab pyvirtualdisplay matplotlib tensorboard
import gym
from itertools import count
import logging
import numpy as np
import matplotlib.pylab as plt
from matplotlib import animation
import platform
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Beta
from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler
import time
from collections import deque
# we need this to run on a headless server
if platform.system() != 'Windows':
from pyvirtualdisplay import Display
display = Display(visible=0, size=(600, 400)).start()
logging.basicConfig(
level=logging.DEBUG,
format='[%(asctime)s] %(message)s',
filename=('car-racing.log'),
)
logger = logging.getLogger('pytorch')
logger.info('Start')
class AnimationWrapper(gym.Wrapper):
def __init__(self, env):
super().__init__(env)
self.env = env
def reset(self):
state, info = self.env.reset()
self.frames = [self.env.render()]
self.rewards = [0]
return state, info
def step(self, action):
next_state, reward, done, truncated, info = self.env.step(action)
self.frames.append(self.env.render())
self.rewards.append(reward)
return next_state, reward, done, truncated, info
def generate(self, filename):
assert len(self.frames) == len(self.rewards)
video = np.array(self.frames)
total_rewards = [0] + np.cumsum(self.rewards).tolist()
fig, ax = plt.subplots(figsize=(4, 4))
im = ax.imshow(video[0,:,:,:])
ax.set_axis_off()
text = ax.text(30, 60, '', color='red')
plt.close() # this is required to not display the generated image
def init():
im.set_data(video[0,:,:,:])
def animate(i):
im.set_data(video[i,:,:,:])
text.set_text(f'Step {i}, total reward: {total_rewards[i]:.2f}')
return im
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=video.shape[0],
interval=100)
anim.save(filename, writer='pillow', dpi=80, fps=24)
env = AnimationWrapper(gym.make("CarRacing-v2", render_mode='rgb_array'))
state = env.reset()
Let’s test the environment with a random policy, limiting the duration to 100 steps.
state, _ = env.reset()
frames = [env.render()]
rewards = [0.0]
for t in count():
env.render()
action = env.action_space.sample()
state, reward, done, truncated, info = env.step(action)
frames.append(env.render())
rewards.append(reward)
# limit to the first 100 steps at most
if done or truncated or t > 100:
break
env.close()
env.generate('car-racing-random.gif')

class Net(nn.Module):
"""
Convolutional Neural Network for PPO
"""
def __init__(self, img_stack):
super(Net, self).__init__()
self.cnn_base = nn.Sequential( # input shape (4, 96, 96)
nn.Conv2d(img_stack, 8, kernel_size=4, stride=2),
nn.ReLU(), # activation
nn.Conv2d(8, 16, kernel_size=3, stride=2), # (8, 47, 47)
nn.ReLU(), # activation
nn.Conv2d(16, 32, kernel_size=3, stride=2), # (16, 23, 23)
nn.ReLU(), # activation
nn.Conv2d(32, 64, kernel_size=3, stride=2), # (32, 11, 11)
nn.ReLU(), # activation
nn.Conv2d(64, 128, kernel_size=3, stride=1), # (64, 5, 5)
nn.ReLU(), # activation
nn.Conv2d(128, 256, kernel_size=3, stride=1), # (128, 3, 3)
nn.ReLU(), # activation
) # output shape (256, 1, 1)
self.v = nn.Sequential(nn.Linear(256, 100), nn.ReLU(), nn.Linear(100, 1))
self.fc = nn.Sequential(nn.Linear(256, 100), nn.ReLU())
self.alpha_head = nn.Sequential(nn.Linear(100, 3), nn.Softplus())
self.beta_head = nn.Sequential(nn.Linear(100, 3), nn.Softplus())
self.apply(self._weights_init)
@staticmethod
def _weights_init(m):
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight, gain=nn.init.calculate_gain('relu'))
nn.init.constant_(m.bias, 0.1)
def forward(self, x):
x = self.cnn_base(x)
x = x.view(-1, 256)
v = self.v(x)
x = self.fc(x)
alpha = self.alpha_head(x) + 1
beta = self.beta_head(x) + 1
return (alpha, beta), v
IMG_STACK = 4
GAMMA = 0.99
EPOCH = 8
MAX_SIZE = 2000 ## CUDA out of mem for max_size=10000
BATCH = 128
EPS = 0.1
LEARNING_RATE = 0.001 # bettr than 0.005 or 0.002
ACTION_REPEAT = 8
transition = np.dtype([('s', np.float64, (IMG_STACK, 96, 96)),
('a', np.float64, (3,)), ('a_logp', np.float64),
('r', np.float64), ('s_', np.float64, (IMG_STACK, 96, 96))])
class Agent():
def __init__(self, device):
self.training_step = 0
self.net = Net(IMG_STACK).double().to(device)
self.buffer = np.empty(MAX_SIZE, dtype=transition)
self.counter = 0
self.device = device
self.optimizer = optim.Adam(self.net.parameters(), lr=LEARNING_RATE) ## lr=1e-3
def select_action(self, state):
state = torch.from_numpy(state).double().to(self.device).unsqueeze(0)
with torch.no_grad():
alpha, beta = self.net(state)[0]
dist = Beta(alpha, beta)
action = dist.sample()
a_logp = dist.log_prob(action).sum(dim=1)
action = action.squeeze().cpu().numpy()
a_logp = a_logp.item()
return action, a_logp
def store(self, transition):
self.buffer[self.counter] = transition
self.counter += 1
if self.counter == MAX_SIZE:
self.counter = 0
return True
else:
return False
def update(self):
self.training_step += 1
s = torch.tensor(self.buffer['s'], dtype=torch.double).to(self.device)
a = torch.tensor(self.buffer['a'], dtype=torch.double).to(self.device)
r = torch.tensor(self.buffer['r'], dtype=torch.double).to(self.device).view(-1, 1)
next_s = torch.tensor(self.buffer['s_'], dtype=torch.double).to(self.device)
old_a_logp = torch.tensor(self.buffer['a_logp'], dtype=torch.double).to(self.device).view(-1, 1)
with torch.no_grad():
target_v = r + GAMMA * self.net(next_s)[1]
adv = target_v - self.net(s)[1]
# adv = (adv - adv.mean()) / (adv.std() + 1e-8)
for _ in range(EPOCH):
for index in BatchSampler(SubsetRandomSampler(range(MAX_SIZE)), BATCH, False):
alpha, beta = self.net(s[index])[0]
dist = Beta(alpha, beta)
a_logp = dist.log_prob(a[index]).sum(dim=1, keepdim=True)
ratio = torch.exp(a_logp - old_a_logp[index])
surr1 = ratio * adv[index]
# clipped function
surr2 = torch.clamp(ratio, 1.0 - EPS, 1.0 + EPS) * adv[index]
action_loss = -torch.min(surr1, surr2).mean()
value_loss = F.smooth_l1_loss(self.net(s[index])[1], target_v[index])
loss = action_loss + 2. * value_loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('device: ', device)
device: cpu
def rgb2gray(rgb, norm=True):
# rgb image -> gray [0, 1]
gray = np.dot(rgb[..., :], [0.299, 0.587, 0.114])
if norm:
# normalize
gray = gray / 128. - 1.
return gray
frame, _, _, _, _ = env.step(np.array([2., 1., 1.]))
img_gray = rgb2gray(frame)
fig, (ax0, ax1) = plt.subplots(ncols=2, nrows=1, figsize=(10, 5))
ax0.imshow(frame)
ax0.set_title('original image')
ax0.set_axis_off()
ax1.imshow(img_gray, cmap='Greys')
ax1.set_title('preprocessed image')
ax1.set_axis_off()

class ObservationWrapper():
def __init__(self, env):
self.env = env
def reset(self):
self.counter = 0
self.av_r = self.reward_memory()
self.die = False
img_rgb, _ = self.env.reset()
img_gray = rgb2gray(img_rgb)
self.stack = [img_gray] * IMG_STACK # four frames for decision
return np.array(self.stack), None
def step(self, action):
total_reward = 0
for i in range(ACTION_REPEAT):
img_rgb, reward, die, truncated, _ = self.env.step(action)
if truncated: die = True
# don't penalize "die state"
if die:
reward += 100
# green penalty
if np.mean(img_rgb[:, :, 1]) > 185.0:
reward -= 0.05
total_reward += reward
# if no reward recently, end the episode
done = True if self.av_r(reward) <= -0.1 else False
if done or die:
break
img_gray = rgb2gray(img_rgb)
self.stack.pop(0)
self.stack.append(img_gray)
assert len(self.stack) == IMG_STACK
return np.array(self.stack), total_reward, done, False, die
def close(self):
return self.env.close()
@staticmethod
def reward_memory():
# record reward for last 100 steps
count = 0
length = 100
history = np.zeros(length)
def memory(reward):
nonlocal count
history[count] = reward
count = (count + 1) % length
return np.mean(history)
return memory
def ppo_train(env, agent, n_episodes, save_every=100):
scores_deque = deque(maxlen=100)
scores_array = []
avg_scores_array = []
timestep_after_last_save = 0
time_start = time.time()
running_score = 0
state = env.reset()
i_lim = 0
for i_episode in range(n_episodes):
timestep = 0
total_reward = 0
## score = 0
state, _ = env.reset()
while True:
action, a_logp = agent.select_action(state)
next_state, reward, done, truncated, die = env.step(
action * np.array([2., 1., 1.]) + np.array([-1., 0., 0.]))
if truncated: done = True
if agent.store((state, action, a_logp, reward, next_state)):
print('updating')
agent.update()
total_reward += reward
state = next_state
timestep += 1
timestep_after_last_save += 1
if done or die:
break
running_score = running_score * 0.99 + total_reward * 0.01
scores_deque.append(total_reward)
scores_array.append(total_reward)
avg_score = np.mean(scores_deque)
avg_scores_array.append(avg_score)
s = (int)(time.time() - time_start)
msg = 'Episode: {} {} score: {:.2f} avg score: {:.2f} run score {:.2f}, \
time: {:02}:{:02}:{:02} '\
.format(i_episode, timestep, \
total_reward, avg_score, running_score, s//3600, s%3600//60, s%60)
logging.info(msg)
print(msg)
return scores_array, avg_scores_array
agent = Agent(device)
env = ObservationWrapper(gym.make('CarRacing-v2'))
NUM_EPISODES = 2_000
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
np.random.seed(seed)
scores, avg_scores = ppo_train(env, agent, NUM_EPISODES)
torch.save(agent.net.state_dict(), 'agent.pt')
Episode: 0 111 score: -22.46 avg score: -22.46 run score -0.22, time: 00:00:07
Episode: 1 108 score: -17.98 avg score: -20.22 run score -0.40, time: 00:00:15
Episode: 2 123 score: -23.11 avg score: -21.18 run score -0.63, time: 00:00:23
Episode: 3 116 score: -17.93 avg score: -20.37 run score -0.80, time: 00:00:31
Episode: 4 111 score: -17.99 avg score: -19.90 run score -0.97, time: 00:00:39
Episode: 5 111 score: -18.03 avg score: -19.58 run score -1.14, time: 00:00:46
Episode: 6 110 score: -17.91 avg score: -19.35 run score -1.31, time: 00:00:54
Episode: 7 104 score: -18.03 avg score: -19.18 run score -1.48, time: 00:01:01
Episode: 8 91 score: 11.97 avg score: -15.72 run score -1.35, time: 00:01:07
Episode: 9 108 score: -17.84 avg score: -15.93 run score -1.51, time: 00:01:14
Episode: 10 125 score: 89.07 avg score: -6.39 run score -0.60, time: 00:01:23
Episode: 11 125 score: 105.69 avg score: 2.95 run score 0.46, time: 00:01:31
Episode: 12 117 score: -18.03 avg score: 1.34 run score 0.27, time: 00:01:39
Episode: 13 111 score: -18.03 avg score: -0.04 run score 0.09, time: 00:01:47
Episode: 14 125 score: 75.60 avg score: 5.00 run score 0.85, time: 00:01:56
Episode: 15 107 score: -18.23 avg score: 3.55 run score 0.66, time: 00:02:03
Episode: 16 117 score: -27.43 avg score: 1.72 run score 0.37, time: 00:02:11
updating
Episode: 923 125 score: 263.80 avg score: 153.50 run score 128.78, time: 01:52:41
Episode: 924 125 score: 345.59 avg score: 156.46 run score 130.94, time: 01:52:49
Episode: 925 125 score: 297.47 avg score: 159.23 run score 132.61, time: 01:52:58
Episode: 926 125 score: 184.00 avg score: 160.51 run score 133.12, time: 01:53:07
Episode: 927 125 score: 264.03 avg score: 162.79 run score 134.43, time: 01:53:16
Episode: 928 125 score: 260.62 avg score: 165.58 run score 135.70, time: 01:53:25
Episode: 929 83 score: 56.03 avg score: 165.84 run score 134.90, time: 01:53:31
Episode: 930 125 score: 248.34 avg score: 167.98 run score 136.03, time: 01:53:40
Episode: 931 125 score: 250.83 avg score: 170.12 run score 137.18, time: 01:53:49
Episode: 932 125 score: 271.88 avg score: 172.62 run score 138.53, time: 01:53:58
Episode: 933 45 score: 41.19 avg score: 170.21 run score 137.55, time: 01:54:01
Episode: 934 96 score: 56.05 avg score: 170.45 run score 136.74, time: 01:54:08
updating
Episode: 935 125 score: 197.37 avg score: 172.02 run score 137.35, time: 01:54:53
Episode: 936 125 score: 350.55 avg score: 172.39 run score 139.48, time: 01:55:02
Episode: 937 125 score: 339.16 avg score: 175.22 run score 141.47, time: 01:55:11
Episode: 938 35 score: 27.49 avg score: 173.28 run score 140.33, time: 01:55:13
Episode: 939 125 score: 238.41 avg score: 173.10 run score 141.32, time: 01:55:22
Episode: 940 44 score: 44.47 avg score: 170.82 run score 140.35, time: 01:55:26
Episode: 941 125 score: 240.51 avg score: 173.40 run score 141.35, time: 01:55:35
Episode: 942 125 score: 284.81 avg score: 175.69 run score 142.78, time: 01:55:44
Episode: 943 125 score: 289.56 avg score: 175.98 run score 144.25, time: 01:55:53
Episode: 944 49 score: 55.24 avg score: 176.26 run score 143.36, time: 01:55:56
Episode: 945 125 score: 317.41 avg score: 179.23 run score 145.10, time: 01:56:05
Episode: 946 125 score: 343.97 avg score: 182.37 run score 147.09, time: 01:56:14
Episode: 947 125 score: 190.87 avg score: 181.80 run score 147.53, time: 01:56:22
Episode: 948 69 score: 86.10 avg score: 179.97 run score 146.91, time: 01:56:27
Episode: 949 78 score: 54.30 avg score: 180.13 run score 145.99, time: 01:56:33
Episode: 950 62 score: 43.72 avg score: 178.32 run score 144.96, time: 01:56:37
Episode: 951 125 score: 337.16 avg score: 181.38 run score 146.89, time: 01:56:46
Episode: 952 125 score: 318.61 avg score: 182.77 run score 148.60, time: 01:56:55
Episode: 953 90 score: 55.33 avg score: 180.85 run score 147.67, time: 01:57:02
Episode: 954 31 score: 23.13 avg score: 178.32 run score 146.43, time: 01:57:04
updating
Episode: 955 125 score: 352.06 avg score: 181.39 run score 148.48, time: 01:57:50
Episode: 956 125 score: 328.86 avg score: 184.39 run score 150.29, time: 01:57:59
Episode: 957 125 score: 334.47 avg score: 185.10 run score 152.13, time: 01:58:08
Episode: 958 76 score: 56.04 avg score: 182.75 run score 151.17, time: 01:58:14
Episode: 959 125 score: 156.15 avg score: 183.95 run score 151.22, time: 01:58:23
Episode: 960 125 score: 385.50 avg score: 185.25 run score 153.56, time: 01:58:31
Episode: 961 106 score: 56.09 avg score: 185.25 run score 152.58, time: 01:58:39
Episode: 962 125 score: 412.21 avg score: 186.77 run score 155.18, time: 01:58:48
Episode: 963 125 score: 219.02 avg score: 187.35 run score 155.82, time: 01:58:57
Episode: 964 125 score: 393.94 avg score: 190.91 run score 158.20, time: 01:59:06
Episode: 965 125 score: 404.41 avg score: 193.19 run score 160.66, time: 01:59:15
Episode: 966 103 score: 56.01 avg score: 191.74 run score 159.62, time: 01:59:22
Episode: 967 125 score: 346.02 avg score: 194.78 run score 161.48, time: 01:59:31
Episode: 968 125 score: 307.69 avg score: 195.07 run score 162.94, time: 01:59:40
Episode: 969 125 score: 306.34 avg score: 195.94 run score 164.38, time: 01:59:49
Episode: 970 125 score: 371.32 avg score: 199.29 run score 166.45, time: 01:59:57
Episode: 971 125 score: 322.15 avg score: 199.61 run score 168.00, time: 02:00:06
updating
Episode: 972 125 score: 312.88 avg score: 202.42 run score 169.45, time: 02:00:53
Episode: 973 125 score: 369.72 avg score: 204.37 run score 171.45, time: 02:01:02
Episode: 974 125 score: 250.00 avg score: 206.69 run score 172.24, time: 02:01:11
Episode: 975 125 score: 400.00 avg score: 210.34 run score 174.52, time: 02:01:20
Episode: 976 125 score: 337.98 avg score: 213.33 run score 176.15, time: 02:01:29
Episode: 977 125 score: 358.87 avg score: 216.79 run score 177.98, time: 02:01:38
Episode: 978 125 score: 367.59 avg score: 218.81 run score 179.88, time: 02:01:46
Episode: 979 119 score: 56.08 avg score: 217.05 run score 178.64, time: 02:01:55
Episode: 980 125 score: 348.62 avg score: 220.31 run score 180.34, time: 02:02:04
Episode: 981 125 score: 262.57 avg score: 220.39 run score 181.16, time: 02:02:14
Episode: 982 125 score: 292.93 avg score: 220.61 run score 182.28, time: 02:02:23
Episode: 983 125 score: 344.37 avg score: 223.70 run score 183.90, time: 02:02:31
Episode: 984 125 score: 262.82 avg score: 223.48 run score 184.69, time: 02:02:40
Episode: 985 103 score: 81.99 avg score: 223.74 run score 183.66, time: 02:02:48
Episode: 986 125 score: 268.04 avg score: 223.82 run score 184.50, time: 02:02:57
Episode: 987 125 score: 336.73 avg score: 227.00 run score 186.03, time: 02:03:06
updating
Episode: 988 125 score: 354.52 avg score: 228.16 run score 187.71, time: 02:03:52
Episode: 989 116 score: 56.07 avg score: 226.28 run score 186.40, time: 02:04:01
Episode: 990 125 score: 312.10 avg score: 226.50 run score 187.65, time: 02:04:10
Episode: 991 125 score: 168.46 avg score: 225.04 run score 187.46, time: 02:04:18
Episode: 992 125 score: 310.34 avg score: 225.66 run score 188.69, time: 02:04:27
Episode: 993 125 score: 363.32 avg score: 228.74 run score 190.44, time: 02:04:36
Episode: 994 93 score: 56.06 avg score: 228.92 run score 189.09, time: 02:04:43
Episode: 995 125 score: 309.90 avg score: 229.26 run score 190.30, time: 02:04:52
Episode: 996 125 score: 361.62 avg score: 230.38 run score 192.01, time: 02:05:01
Episode: 997 125 score: 335.64 avg score: 233.40 run score 193.45, time: 02:05:10
Episode: 998 125 score: 168.92 avg score: 232.13 run score 193.20, time: 02:05:18
Episode: 999 125 score: 341.30 avg score: 235.15 run score 194.68, time: 02:05:27
Episode: 1000 125 score: 164.84 avg score: 234.69 run score 194.39, time: 02:05:36
Episode: 1001 125 score: 286.98 avg score: 237.00 run score 195.31, time: 02:05:46
Episode: 1002 125 score: 349.82 avg score: 239.94 run score 196.86, time: 02:05:55
Episode: 1003 125 score: 359.74 avg score: 242.98 run score 198.49, time: 02:06:04
updating
Episode: 1004 125 score: 326.39 avg score: 243.87 run score 199.77, time: 02:06:50
Episode: 1005 125 score: 326.32 avg score: 246.87 run score 201.03, time: 02:06:59
Episode: 1006 125 score: 332.18 avg score: 247.61 run score 202.34, time: 02:07:08
Episode: 1007 125 score: 315.99 avg score: 247.65 run score 203.48, time: 02:07:16
Episode: 1008 125 score: 373.24 avg score: 247.80 run score 205.18, time: 02:07:25
Episode: 1009 125 score: 337.42 avg score: 248.16 run score 206.50, time: 02:07:34
Episode: 1010 125 score: 175.82 avg score: 247.48 run score 206.19, time: 02:07:43
Episode: 1011 125 score: 281.90 avg score: 247.93 run score 206.95, time: 02:07:52
Episode: 1012 125 score: 335.79 avg score: 248.64 run score 208.24, time: 02:08:01
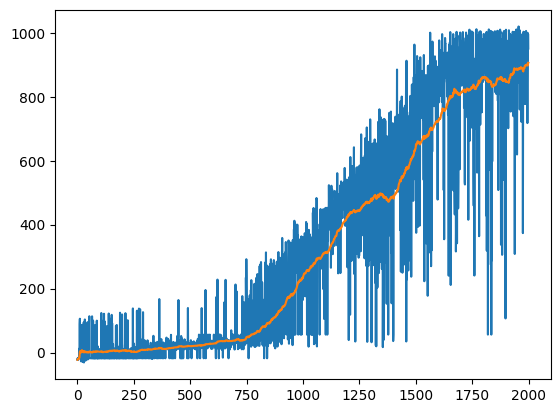
plt.plot(scores)
plt.plot(avg_scores)
[<matplotlib.lines.Line2D at 0x7feb09081c40>]
# agent = Agent(device)
# agent.net.load_state_dict(torch.load('agent.pt'))
env = ObservationWrapper(AnimationWrapper(gym.make('CarRacing-v2', render_mode='rgb_array')))
state, _ = env.reset()
for t in count():
action, a_logp = agent.select_action(state)
next_state, reward, done, truncated, die = env.step( \
action * np.array([2., 1., 1.]) + np.array([-1., 0., 0.]))
if done or truncated or t > 1_000:
break
state = next_state
print(f"# steps: {t}")
env.close()
# steps: 1001
env.env.generate('car-racing-video.gif')
