The CIFAR100 dataset is a labeled dataset of 60,000 coloured images of size 32x32. All images are equally divided to 100 different classes; it is a classification task similar to the CIFAR 10, but with more classes. The main challenge of this dataset is to come up with a model that can successfully categorize an image to one of 100 classes given only a small number of images per class (600). There are 500 training images and 100 testing images per class. The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a “fine” label (the class to which it belongs) and a “coarse” label (the superclass to which it belongs).
From the author’s website, here there are the classes:
| Superclass | Classes |
|---|---|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television |
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
We will use the ResNet model presented in the 2015 paper Deep Residual Learning for Image Recognition.
! pip install -U pip
! pip install numpy pandas matplotlib seaborn ipykernel scikit-learn nbconvert
! pip install torch torchvision torchinfo
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: pip in /usr/local/lib/python3.7/dist-packages (21.1.3)
Collecting pip
Downloading pip-22.3.1-py3-none-any.whl (2.1 MB)
[K |████████████████████████████████| 2.1 MB 14.2 MB/s
[?25hInstalling collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 21.1.3
Uninstalling pip-21.1.3:
Successfully uninstalled pip-21.1.3
Successfully installed pip-22.3.1
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (1.21.6)
Requirement already satisfied: pandas in /usr/local/lib/python3.7/dist-packages (1.3.5)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.7/dist-packages (3.2.2)
Requirement already satisfied: seaborn in /usr/local/lib/python3.7/dist-packages (0.11.2)
Requirement already satisfied: ipykernel in /usr/local/lib/python3.7/dist-packages (5.3.4)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.7/dist-packages (1.0.2)
Requirement already satisfied: nbconvert in /usr/local/lib/python3.7/dist-packages (5.6.1)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas) (2022.6)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas) (2.8.2)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (0.11.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (3.0.9)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib) (1.4.4)
Requirement already satisfied: scipy>=1.0 in /usr/local/lib/python3.7/dist-packages (from seaborn) (1.7.3)
Requirement already satisfied: traitlets>=4.1.0 in /usr/local/lib/python3.7/dist-packages (from ipykernel) (5.1.1)
Requirement already satisfied: jupyter-client in /usr/local/lib/python3.7/dist-packages (from ipykernel) (6.1.12)
Requirement already satisfied: tornado>=4.2 in /usr/local/lib/python3.7/dist-packages (from ipykernel) (6.0.4)
Requirement already satisfied: ipython>=5.0.0 in /usr/local/lib/python3.7/dist-packages (from ipykernel) (7.9.0)
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn) (1.2.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn) (3.1.0)
Requirement already satisfied: nbformat>=4.4 in /usr/local/lib/python3.7/dist-packages (from nbconvert) (5.7.0)
Requirement already satisfied: pandocfilters>=1.4.1 in /usr/local/lib/python3.7/dist-packages (from nbconvert) (1.5.0)
Requirement already satisfied: bleach in /usr/local/lib/python3.7/dist-packages (from nbconvert) (5.0.1)
Requirement already satisfied: testpath in /usr/local/lib/python3.7/dist-packages (from nbconvert) (0.6.0)
Requirement already satisfied: pygments in /usr/local/lib/python3.7/dist-packages (from nbconvert) (2.6.1)
Requirement already satisfied: jupyter-core in /usr/local/lib/python3.7/dist-packages (from nbconvert) (4.11.2)
Requirement already satisfied: mistune<2,>=0.8.1 in /usr/local/lib/python3.7/dist-packages (from nbconvert) (0.8.4)
Requirement already satisfied: jinja2>=2.4 in /usr/local/lib/python3.7/dist-packages (from nbconvert) (2.11.3)
Requirement already satisfied: entrypoints>=0.2.2 in /usr/local/lib/python3.7/dist-packages (from nbconvert) (0.4)
Requirement already satisfied: defusedxml in /usr/local/lib/python3.7/dist-packages (from nbconvert) (0.7.1)
Requirement already satisfied: setuptools>=18.5 in /usr/local/lib/python3.7/dist-packages (from ipython>=5.0.0->ipykernel) (57.4.0)
Requirement already satisfied: prompt-toolkit<2.1.0,>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from ipython>=5.0.0->ipykernel) (2.0.10)
Requirement already satisfied: decorator in /usr/local/lib/python3.7/dist-packages (from ipython>=5.0.0->ipykernel) (4.4.2)
Collecting jedi>=0.10
Downloading jedi-0.18.1-py2.py3-none-any.whl (1.6 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.6/1.6 MB[0m [31m41.7 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: backcall in /usr/local/lib/python3.7/dist-packages (from ipython>=5.0.0->ipykernel) (0.2.0)
Requirement already satisfied: pexpect in /usr/local/lib/python3.7/dist-packages (from ipython>=5.0.0->ipykernel) (4.8.0)
Requirement already satisfied: pickleshare in /usr/local/lib/python3.7/dist-packages (from ipython>=5.0.0->ipykernel) (0.7.5)
Requirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.7/dist-packages (from jinja2>=2.4->nbconvert) (2.0.1)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from kiwisolver>=1.0.1->matplotlib) (4.1.1)
Requirement already satisfied: fastjsonschema in /usr/local/lib/python3.7/dist-packages (from nbformat>=4.4->nbconvert) (2.16.2)
Requirement already satisfied: importlib-metadata>=3.6 in /usr/local/lib/python3.7/dist-packages (from nbformat>=4.4->nbconvert) (4.13.0)
Requirement already satisfied: jsonschema>=2.6 in /usr/local/lib/python3.7/dist-packages (from nbformat>=4.4->nbconvert) (4.3.3)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas) (1.15.0)
Requirement already satisfied: webencodings in /usr/local/lib/python3.7/dist-packages (from bleach->nbconvert) (0.5.1)
Requirement already satisfied: pyzmq>=13 in /usr/local/lib/python3.7/dist-packages (from jupyter-client->ipykernel) (23.2.1)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata>=3.6->nbformat>=4.4->nbconvert) (3.10.0)
Requirement already satisfied: parso<0.9.0,>=0.8.0 in /usr/local/lib/python3.7/dist-packages (from jedi>=0.10->ipython>=5.0.0->ipykernel) (0.8.3)
Requirement already satisfied: pyrsistent!=0.17.0,!=0.17.1,!=0.17.2,>=0.14.0 in /usr/local/lib/python3.7/dist-packages (from jsonschema>=2.6->nbformat>=4.4->nbconvert) (0.19.2)
Requirement already satisfied: attrs>=17.4.0 in /usr/local/lib/python3.7/dist-packages (from jsonschema>=2.6->nbformat>=4.4->nbconvert) (22.1.0)
Requirement already satisfied: importlib-resources>=1.4.0 in /usr/local/lib/python3.7/dist-packages (from jsonschema>=2.6->nbformat>=4.4->nbconvert) (5.10.0)
Requirement already satisfied: wcwidth in /usr/local/lib/python3.7/dist-packages (from prompt-toolkit<2.1.0,>=2.0.0->ipython>=5.0.0->ipykernel) (0.2.5)
Requirement already satisfied: ptyprocess>=0.5 in /usr/local/lib/python3.7/dist-packages (from pexpect->ipython>=5.0.0->ipykernel) (0.7.0)
Installing collected packages: jedi
Successfully installed jedi-0.18.1
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mLooking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: torch in /usr/local/lib/python3.7/dist-packages (1.12.1+cu113)
Requirement already satisfied: torchvision in /usr/local/lib/python3.7/dist-packages (0.13.1+cu113)
Collecting torchinfo
Downloading torchinfo-1.7.1-py3-none-any.whl (22 kB)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torch) (4.1.1)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.7/dist-packages (from torchvision) (7.1.2)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from torchvision) (1.21.6)
Requirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from torchvision) (2.23.0)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (1.24.3)
Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (3.0.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (2022.9.24)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->torchvision) (2.10)
Installing collected packages: torchinfo
Successfully installed torchinfo-1.7.1
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0m
The Python code is run in the virtual environment defined below.
python -m venv venv
.\venv\Scripts\activate.ps1
pip install -U pip
pip install numpy pandas matplotlib seaborn ipykernel scikit-learn nbconvert
pip install torch torchvision torchinfo
import sys
print('Python version:', sys.version)
Python version: 3.7.15 (default, Oct 12 2022, 19:14:55)
[GCC 7.5.0]
from collections import defaultdict
import torch
import torchvision
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
from torchvision.datasets.utils import download_url
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.utils.data import random_split
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device {device}.')
Using device cuda.
Let’s first load the original data without any transformation to see what the images are.
dataset_train = torchvision.datasets.CIFAR100(root='./dataset', train=True, download=True)
num_classes = len(dataset_train.classes)
print(f"Found {len(dataset_train)} entries and {num_classes} classes in the train dataset.")
dataset_test = torchvision.datasets.CIFAR100(root='./dataset', train=False, download=True)
print(f"Found {len(dataset_test)} entries and {len(dataset_test.classes)} classes in the test dataset.")
assert len(set(dataset_train.classes) - set(dataset_test.classes)) == 0
Downloading https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz to ./dataset/cifar-100-python.tar.gz
0%| | 0/169001437 [00:00<?, ?it/s]
Extracting ./dataset/cifar-100-python.tar.gz to ./dataset
Found 50000 entries and 100 classes in the train dataset.
Files already downloaded and verified
Found 10000 entries and 100 classes in the test dataset.
The dataset is balanced, with each class having 500 training images and 100 test images. This is true for both the fine and the coarse classes.
num_items_per_class = {k: [0, 0] for k in dataset_train.classes}
for item in dataset_train:
label = dataset_train.classes[item[1]]
num_items_per_class[label][0] += 1
for item in dataset_test:
label = dataset_test.classes[item[1]]
num_items_per_class[label][1] += 1
import pandas as pd
pd.DataFrame(num_items_per_class).T
| 0 | 1 | |
|---|---|---|
| apple | 500 | 100 |
| aquarium_fish | 500 | 100 |
| baby | 500 | 100 |
| bear | 500 | 100 |
| beaver | 500 | 100 |
| ... | ... | ... |
| whale | 500 | 100 |
| willow_tree | 500 | 100 |
| wolf | 500 | 100 |
| woman | 500 | 100 |
| worm | 500 | 100 |
100 rows × 2 columns
We plot a few of the training and test datasets. The images are quite small and it is not always easy to understand the category. From the (small) sample there is no difference between training and test images.
n = 5
fig, axes = plt.subplots(nrows=n, ncols=2 * n, figsize=(10, 5))
for i in range(n):
for j in range(2 * n):
img, cat = dataset_train[i + 2 * n * j]
axes[i][j].imshow(img)
axes[i][j].set_title(dataset_train.classes[cat], fontsize=10)
axes[i][j].axis('off')
fig.tight_layout()
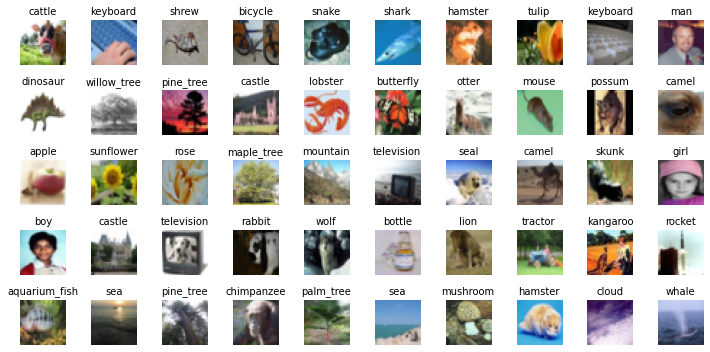
n = 5
fig, axes = plt.subplots(nrows=n, ncols=2 * n, figsize=(10, 5))
for i in range(n):
for j in range(2 * n):
img, cat = dataset_train[i + 2 * n * j]
axes[i][j].imshow(img)
axes[i][j].set_title(dataset_test.classes[cat], fontsize=10)
axes[i][j].axis('off')
fig.tight_layout()
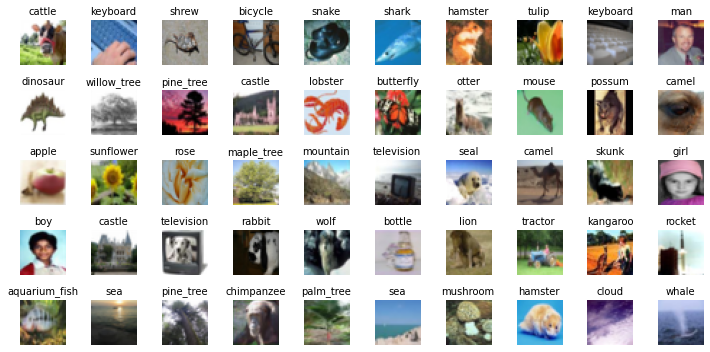
It is good practice to normalize the data. We do this using the training dataset only.
sums = []
for img, _ in dataset_train:
sums.append((transforms.ToTensor()(img).sum((1, 2)) / 32 / 32).tolist())
sums = np.array(sums)
We are ready to define the transformations to be applied to the training and validation datsets. For the former we use random crop and a random horizontal flip, followed by a transformation to tensor and normalization; for the latter we skip the randomness and only apply the transformation to tensor and the normalization. We then reload the datasets with the proper transformations.
stats = sums.mean(axis=0).tolist(), sums.std(axis=0).tolist()
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4, padding_mode='reflect'),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(*stats,inplace=True),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(*stats),
])
dataset_train = torchvision.datasets.CIFAR100(root='./dataset', train=True, download=False, transform=transform_train)
dataset_test = torchvision.datasets.CIFAR100(root='./dataset', train=False, download=False, transform=transform_test)
We will load the data using a batch size of 256. Because of the normalization, the images look strange to us.
batch_size = 256
dataloader_train = DataLoader(dataset_train, batch_size, shuffle=True, pin_memory=True)
dataloader_test = DataLoader(dataset_test, batch_size, pin_memory=True)
for images, _ in dataloader_train:
fig, ax = plt.subplots(figsize=(10, 10))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images[:100].clip(0.0, 1.0), nrow=10).permute(1, 2, 0))
break

class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, downsample):
super().__init__()
if downsample:
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2),
nn.BatchNorm2d(out_channels)
)
else:
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.shortcut = nn.Sequential()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, input):
shortcut = self.shortcut(input)
input = nn.ReLU()(self.bn1(self.conv1(input)))
input = nn.ReLU()(self.bn2(self.conv2(input)))
input = input + shortcut
return nn.ReLU()(input)
class ResNet(nn.Module):
def __init__(self, in_channels, resblock, outputs):
super().__init__()
n = 64
self.layer0 = nn.Sequential(
nn.Conv2d(in_channels, n, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(n),
nn.ReLU()
)
self.layer1 = nn.Sequential(
resblock(n, n, downsample=False),
resblock(n, n, downsample=False)
)
self.layer2 = nn.Sequential(
resblock(n, 2 * n, downsample=True),
resblock(2* n, 2 * n, downsample=False)
)
self.layer3 = nn.Sequential(
resblock(2 * n, 2 * n, downsample=True),
resblock(2 * n, 2 * n, downsample=False)
)
self.layer4 = nn.Sequential(
resblock(2 * n, 2 * n, downsample=False),
resblock(2 * n, 2 * n, downsample=False)
)
self.gap = torch.nn.AdaptiveAvgPool2d(1)
self.fc = torch.nn.Linear(128, outputs)
def forward(self, input):
input = self.layer0(input)
input = self.layer1(input)
input = self.layer2(input)
input = self.layer3(input)
input = self.layer4(input)
input = self.gap(input)
input = input.view(input.size(0), -1)
input = self.fc(input)
return input
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
def init_weights(m):
if isinstance(m, nn.Linear):
torch.nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
from torchinfo import summary
model = ResNet(3, ResBlock, outputs=num_classes).to(device)
summary(model, (2, 3, 32, 32))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [2, 100] --
├─Sequential: 1-1 [2, 64, 16, 16] --
│ └─Conv2d: 2-1 [2, 64, 32, 32] 1,792
│ └─MaxPool2d: 2-2 [2, 64, 16, 16] --
│ └─BatchNorm2d: 2-3 [2, 64, 16, 16] 128
│ └─ReLU: 2-4 [2, 64, 16, 16] --
├─Sequential: 1-2 [2, 64, 16, 16] --
│ └─ResBlock: 2-5 [2, 64, 16, 16] --
│ │ └─Sequential: 3-1 [2, 64, 16, 16] --
│ │ └─Conv2d: 3-2 [2, 64, 16, 16] 36,928
│ │ └─BatchNorm2d: 3-3 [2, 64, 16, 16] 128
│ │ └─Conv2d: 3-4 [2, 64, 16, 16] 36,928
│ │ └─BatchNorm2d: 3-5 [2, 64, 16, 16] 128
│ └─ResBlock: 2-6 [2, 64, 16, 16] --
│ │ └─Sequential: 3-6 [2, 64, 16, 16] --
│ │ └─Conv2d: 3-7 [2, 64, 16, 16] 36,928
│ │ └─BatchNorm2d: 3-8 [2, 64, 16, 16] 128
│ │ └─Conv2d: 3-9 [2, 64, 16, 16] 36,928
│ │ └─BatchNorm2d: 3-10 [2, 64, 16, 16] 128
├─Sequential: 1-3 [2, 128, 8, 8] --
│ └─ResBlock: 2-7 [2, 128, 8, 8] --
│ │ └─Sequential: 3-11 [2, 128, 8, 8] 8,576
│ │ └─Conv2d: 3-12 [2, 128, 8, 8] 73,856
│ │ └─BatchNorm2d: 3-13 [2, 128, 8, 8] 256
│ │ └─Conv2d: 3-14 [2, 128, 8, 8] 147,584
│ │ └─BatchNorm2d: 3-15 [2, 128, 8, 8] 256
│ └─ResBlock: 2-8 [2, 128, 8, 8] --
│ │ └─Sequential: 3-16 [2, 128, 8, 8] --
│ │ └─Conv2d: 3-17 [2, 128, 8, 8] 147,584
│ │ └─BatchNorm2d: 3-18 [2, 128, 8, 8] 256
│ │ └─Conv2d: 3-19 [2, 128, 8, 8] 147,584
│ │ └─BatchNorm2d: 3-20 [2, 128, 8, 8] 256
├─Sequential: 1-4 [2, 128, 4, 4] --
│ └─ResBlock: 2-9 [2, 128, 4, 4] --
│ │ └─Sequential: 3-21 [2, 128, 4, 4] 16,768
│ │ └─Conv2d: 3-22 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-23 [2, 128, 4, 4] 256
│ │ └─Conv2d: 3-24 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-25 [2, 128, 4, 4] 256
│ └─ResBlock: 2-10 [2, 128, 4, 4] --
│ │ └─Sequential: 3-26 [2, 128, 4, 4] --
│ │ └─Conv2d: 3-27 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-28 [2, 128, 4, 4] 256
│ │ └─Conv2d: 3-29 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-30 [2, 128, 4, 4] 256
├─Sequential: 1-5 [2, 128, 4, 4] --
│ └─ResBlock: 2-11 [2, 128, 4, 4] --
│ │ └─Sequential: 3-31 [2, 128, 4, 4] --
│ │ └─Conv2d: 3-32 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-33 [2, 128, 4, 4] 256
│ │ └─Conv2d: 3-34 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-35 [2, 128, 4, 4] 256
│ └─ResBlock: 2-12 [2, 128, 4, 4] --
│ │ └─Sequential: 3-36 [2, 128, 4, 4] --
│ │ └─Conv2d: 3-37 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-38 [2, 128, 4, 4] 256
│ │ └─Conv2d: 3-39 [2, 128, 4, 4] 147,584
│ │ └─BatchNorm2d: 3-40 [2, 128, 4, 4] 256
├─AdaptiveAvgPool2d: 1-6 [2, 128, 1, 1] --
├─Linear: 1-7 [2, 100] 12,900
==========================================================================================
Total params: 1,888,740
Trainable params: 1,888,740
Non-trainable params: 0
Total mult-adds (M): 184.83
==========================================================================================
Input size (MB): 0.02
Forward/backward pass size (MB): 5.31
Params size (MB): 7.55
Estimated Total Size (MB): 12.89
==========================================================================================
torch.manual_seed(42)
model.apply(init_weights)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-3)
#scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=optimizer, gamma=0.95)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=1)
epochs = 20
loss_history_train, loss_history_test = [], []
accuracy_history_train, accuracy_history_test = [], []
for epoch in range(1, epochs + 1):
total_loss_train, total_accuracy_train = 0.0, 0.0
total_loss_test, total_accuracy_test = 0, 0
model.train()
for inputs, labels in dataloader_train:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = F.cross_entropy(outputs, labels)
optimizer.zero_grad()
loss.backward()
# prevent too large gradients
nn.utils.clip_grad_value_(model.parameters(), 0.1)
optimizer.step()
_, preds = torch.max(outputs, 1)
total_loss_train += loss.item()
total_accuracy_train += torch.sum(preds == labels.data).item()
scheduler.step()
with torch.no_grad():
model.eval()
for inputs, labels in dataloader_test:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = F.cross_entropy(outputs, labels)
_, preds = torch.max(outputs, 1)
total_loss_test += loss.item()
total_accuracy_test += torch.sum(preds == labels.data).item()
total_loss_train /= len(dataset_train)
total_accuracy_train /= len(dataset_train)
loss_history_train.append(total_loss_train)
accuracy_history_train.append(total_accuracy_train)
total_loss_test /= len(dataset_test)
total_accuracy_test /= len(dataset_test)
loss_history_test.append(total_loss_test)
accuracy_history_test.append(total_accuracy_test)
print(f"epoch {epoch:2d}, lr = {scheduler.get_last_lr()[0]:.2e}, ", end='')
print(f"train: loss = {total_loss_train:.4f}, accuracy = {total_accuracy_train:.4%}, ", end='')
print(f"test: loss = {total_loss_test:.4f}, accuracy = {total_accuracy_test:.4%}")
epoch 1, lr = 1.00e-03, train: loss = 0.0154, accuracy = 10.7940%, test: loss = 0.0141, accuracy = 15.8300%
epoch 2, lr = 1.00e-03, train: loss = 0.0123, accuracy = 22.2780%, test: loss = 0.0118, accuracy = 25.6500%
epoch 3, lr = 1.00e-03, train: loss = 0.0106, accuracy = 30.3500%, test: loss = 0.0115, accuracy = 27.9000%
epoch 4, lr = 1.00e-03, train: loss = 0.0095, accuracy = 36.2460%, test: loss = 0.0101, accuracy = 35.1000%
epoch 5, lr = 1.00e-03, train: loss = 0.0087, accuracy = 40.6280%, test: loss = 0.0091, accuracy = 40.3500%
epoch 6, lr = 1.00e-03, train: loss = 0.0082, accuracy = 43.4220%, test: loss = 0.0087, accuracy = 41.8300%
epoch 7, lr = 1.00e-03, train: loss = 0.0077, accuracy = 46.8540%, test: loss = 0.0084, accuracy = 43.5000%
epoch 8, lr = 1.00e-03, train: loss = 0.0073, accuracy = 49.2740%, test: loss = 0.0082, accuracy = 44.9100%
epoch 9, lr = 1.00e-03, train: loss = 0.0070, accuracy = 50.6760%, test: loss = 0.0080, accuracy = 46.3500%
epoch 10, lr = 1.00e-03, train: loss = 0.0067, accuracy = 52.4740%, test: loss = 0.0078, accuracy = 47.2200%
epoch 11, lr = 1.00e-03, train: loss = 0.0065, accuracy = 53.5460%, test: loss = 0.0078, accuracy = 47.1200%
epoch 12, lr = 1.00e-03, train: loss = 0.0062, accuracy = 55.8080%, test: loss = 0.0072, accuracy = 50.4200%
epoch 13, lr = 1.00e-03, train: loss = 0.0060, accuracy = 56.7320%, test: loss = 0.0073, accuracy = 50.5600%
epoch 14, lr = 1.00e-03, train: loss = 0.0059, accuracy = 57.6900%, test: loss = 0.0073, accuracy = 49.9900%
epoch 15, lr = 1.00e-03, train: loss = 0.0058, accuracy = 58.5080%, test: loss = 0.0071, accuracy = 52.6100%
epoch 16, lr = 1.00e-03, train: loss = 0.0056, accuracy = 59.2180%, test: loss = 0.0068, accuracy = 53.6800%
epoch 17, lr = 1.00e-03, train: loss = 0.0055, accuracy = 59.8520%, test: loss = 0.0070, accuracy = 53.0100%
epoch 18, lr = 1.00e-03, train: loss = 0.0054, accuracy = 60.4660%, test: loss = 0.0063, accuracy = 56.2900%
epoch 19, lr = 1.00e-03, train: loss = 0.0053, accuracy = 61.7920%, test: loss = 0.0074, accuracy = 50.9400%
epoch 20, lr = 1.00e-03, train: loss = 0.0052, accuracy = 62.0320%, test: loss = 0.0063, accuracy = 56.5900%
model.eval()
topk_accuracies_test = [0, 0, 0, 0]
for inputs, labels in dataloader_test:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
for i, k in enumerate([1, 2, 5, 10]):
_, pred = outputs.topk(k, dim=1, largest=True, sorted=True)
pred = pred.t()
correct = pred.eq(labels.view(1, -1).expand_as(pred))
topk_accuracies_test[i] += sum(correct.sum(dim=0)).cpu().item()
topk_accuracies_test = np.array(topk_accuracies_test) / len(dataset_test)
print(f"topk(1) accuracy: {topk_accuracies_test[0]:.2%}")
print(f"topk(2) accuracy: {topk_accuracies_test[1]:.2%}")
print(f"topk(5) accuracy: {topk_accuracies_test[2]:.2%}")
print(f"topk(10) accuracy: {topk_accuracies_test[3]:.2%}")
topk(1) accuracy: 56.59%
topk(2) accuracy: 70.55%
topk(5) accuracy: 84.71%
topk(10) accuracy: 91.77%
from sklearn.metrics import confusion_matrix, classification_report, f1_score, recall_score, accuracy_score, precision_recall_fscore_support
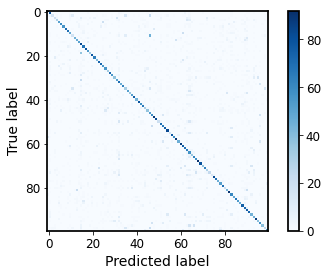
Generate testing accuracy, predicted label, confusion matrix, and table for classification report.
def test_label_predictions(model, device, test_loader):
model.eval()
actuals = []
predictions = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
prediction = output.argmax(dim=1, keepdim=True)
actuals.extend(target.view_as(prediction))
predictions.extend(prediction)
return [i.item() for i in actuals], [i.item() for i in predictions]
y_test, y_pred = test_label_predictions(model, device, dataloader_test)
cm = confusion_matrix(y_test, y_pred)
cr = classification_report(y_test, y_pred)
fs = f1_score(y_test,y_pred,average='weighted')
rs = recall_score(y_test, y_pred,average='weighted')
accuracy = accuracy_score(y_test, y_pred)
print(f'F1 score: {fs}')
print(f'Recall score: {rs}')
print(f'Accuracy score: {accuracy}')
F1 score: 0.5599094871093443
Recall score: 0.5659
Accuracy score: 0.5659
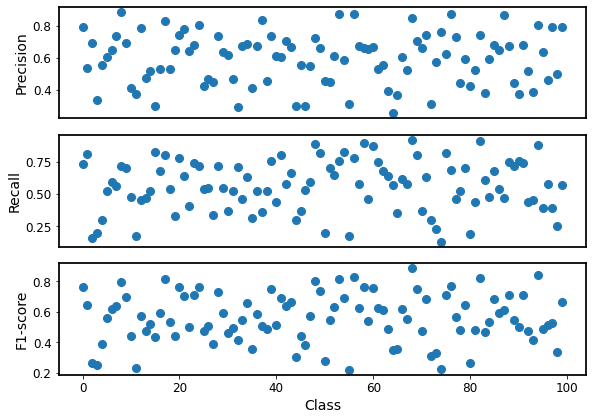
precision, recall, f1,_= precision_recall_fscore_support(y_test, y_pred)
plt.rcParams['font.size'] = 12
plt.rc('axes', linewidth=1.75)
marker_size = 8
figsize = 6
plt.figure(figsize=(1.4 * figsize, figsize))
plt.subplot(3, 1, 1)
plt.plot(precision, 'o', markersize=marker_size)
# plt.legend(loc=0)
# plt.yticks(np.arange(0.5, 1.01, 0.1))
plt.ylabel('Precision', fontsize=14)
plt.xticks([])
plt.subplot(3, 1, 2)
plt.plot(recall, 'o', markersize=marker_size)
# plt.yticks(np.arange(0.5, 1.01, 0.1))
plt.ylabel('Recall', fontsize=14)
plt.xticks([])
plt.subplot(3, 1, 3)
plt.plot(f1, 'o', markersize=marker_size)
# plt.yticks(np.arange(0.5, 1.01, 0.1))
plt.ylabel('F1-score', fontsize=14)
plt.xlabel('Class', fontsize=14)
plt.subplots_adjust(hspace=0.001)
plt.tight_layout()
plt.savefig("classification.pdf")
plt.figure()
plt.imshow(cm, interpolation='nearest', cmap=plt.get_cmap('Blues'))
plt.colorbar()
plt.ylabel('True label', fontsize=14)
plt.xlabel('Predicted label', fontsize=14)
plt.tight_layout()
plt.savefig("confusion_matrix.pdf")
plt.show()
from PIL import Image
import urllib.request
plt.rc('xtick', labelsize=10)
def test_image(url):
with urllib.request.urlopen(url) as url:
img_orig = Image.open(url)
img = img_orig.resize((32, 32))
outputs = model(transform_test(img).unsqueeze(0).to(device))
probs, pred = outputs.topk(5, dim=1, largest=True, sorted=True)
fig, (ax0, ax1, ax2) = plt.subplots(figsize=(12, 4), ncols=3)
ax0.imshow(img_orig)
ax1.imshow(img)
ax0.axis('off'); ax1.axis('off')
classes = [dataset_test.classes[k] for k in pred[0].cpu().numpy()]
ax2.bar(classes, probs[0].detach().cpu())
test_image('https://upload.wikimedia.org/wikipedia/commons/e/e3/Oranges_-_whole-halved-segment.jpg')

test_image('https://upload.wikimedia.org/wikipedia/commons/4/41/Left_side_of_Flying_Pigeon.jpg')

test_image('https://upload.wikimedia.org/wikipedia/commons/6/6b/American_Beaver.jpg')

test_image('https://upload.wikimedia.org/wikipedia/commons/3/3f/Walking_tiger_female.jpg')

test_image('https://upload.wikimedia.org/wikipedia/commons/5/5f/Kolm%C3%A5rden_Wolf.jpg')
