conda create –name intel-image-classification –no-default-packages -y python==3.8 conda activate intel-image-classification pip install numpy pandas matplotlib seaborn jupyterlab ipykernel scikit-learn nbconvert pip install torch torchvision pip install torchsummary pip install tqdm kaggle
import matplotlib.pylab as plt
import torch
import torchvision
from torch import nn, optim
from torchvision import datasets, transforms, models
from pathlib import Path
from PIL import Image
from prettytable import PrettyTable
from tqdm import tqdm
def create_table(headers,rows):
table = PrettyTable(headers)
for row in rows:
table.add_row(row)
return table
dir_train = "data/seg_train/seg_train"
dir_test = "data/seg_test/seg_test"
# rows = []
# for c in dataset_train.classes:
# path = Path(dir_train) / c
# num_items_train = len(list(path.glob('*')))
# path = Path(dir_test) / c
# num_items_test = len(list(path.glob('*')))
# rows.append((c, num_items_train, num_items_test))
# create_table(['class', 'train', 'test'], rows)
transform_train = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(),
transforms.RandomAffine(0, shear=10, scale=(0.8,1.2)),
transforms.ColorJitter(brightness=1, contrast=1, saturation=1),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
training_dataset = datasets.ImageFolder(dir_train, transform=transform_train)
validation_dataset = datasets.ImageFolder(dir_test, transform=transform)
print(f"# train entries: {len(training_dataset)}, # test entries: {len(validation_dataset)}")
training_loader = torch.utils.data.DataLoader(training_dataset, batch_size=20, shuffle=True)
validation_loader = torch.utils.data.DataLoader(validation_dataset, batch_size = 20, shuffle=False)
# train entries: 14034, # test entries: 3000
idx_to_classes = {v: k for k, v in validation_dataset.class_to_idx.items()}
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Device: {device}")
Device: cpu
model = models.vgg16(weights=models.VGG16_Weights.DEFAULT)
for param in model.features.parameters():
param.requires_grad = False
import torch.nn as nn
n_inputs = model.classifier[6].in_features
last_layer = nn.Linear(n_inputs, 6)
model.classifier[6] = last_layer
model.to(device)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=6, bias=True)
)
)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
epochs = 5
running_loss_history = []
running_corrects_history = []
val_running_loss_history = []
val_running_corrects_history = []
for e in range(epochs):
running_loss = 0.0
running_corrects = 0.0
val_running_loss = 0.0
val_running_corrects = 0.0
for inputs, labels in tqdm(training_loader, ncols=100):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.item()
running_corrects += torch.sum(preds == labels.data)
else:
with torch.no_grad():
for val_inputs, val_labels in tqdm(validation_loader, ncols=100):
val_inputs = val_inputs.to(device)
val_labels = val_labels.to(device)
val_outputs = model(val_inputs)
val_loss = criterion(val_outputs, val_labels)
_, val_preds = torch.max(val_outputs, 1)
val_running_loss += val_loss.item()
val_running_corrects += torch.sum(val_preds == val_labels.data)
epoch_loss = running_loss/len(training_loader.dataset)
epoch_acc = running_corrects.float()/ len(training_loader.dataset)
running_loss_history.append(epoch_loss)
running_corrects_history.append(epoch_acc)
val_epoch_loss = val_running_loss/len(validation_loader.dataset)
val_epoch_acc = val_running_corrects.float()/ len(validation_loader.dataset)
val_running_loss_history.append(val_epoch_loss)
val_running_corrects_history.append(val_epoch_acc)
print('epoch :', (e+1))
print('training loss: {:.4f}, acc {:.4f} '.format(epoch_loss, epoch_acc.item()))
print('validation loss: {:.4f}, validation acc {:.4f} '.format(val_epoch_loss, val_epoch_acc.item()))
100%|█████████████████████████████████████████████████████████████| 702/702 [03:41<00:00, 3.16it/s]
100%|█████████████████████████████████████████████████████████████| 150/150 [00:23<00:00, 6.34it/s]
epoch : 1
training loss: 0.0293, acc 0.7725
validation loss: 0.0147, validation acc 0.8960
100%|█████████████████████████████████████████████████████████████| 702/702 [02:51<00:00, 4.09it/s]
100%|█████████████████████████████████████████████████████████████| 150/150 [00:24<00:00, 6.16it/s]
epoch : 2
training loss: 0.0233, acc 0.8192
validation loss: 0.0142, validation acc 0.8977
100%|█████████████████████████████████████████████████████████████| 702/702 [02:54<00:00, 4.03it/s]
100%|█████████████████████████████████████████████████████████████| 150/150 [00:24<00:00, 6.12it/s]
epoch : 3
training loss: 0.0216, acc 0.8327
validation loss: 0.0135, validation acc 0.9067
100%|█████████████████████████████████████████████████████████████| 702/702 [02:55<00:00, 4.01it/s]
100%|█████████████████████████████████████████████████████████████| 150/150 [00:24<00:00, 6.10it/s]
epoch : 4
training loss: 0.0204, acc 0.8427
validation loss: 0.0144, validation acc 0.8967
100%|█████████████████████████████████████████████████████████████| 702/702 [02:55<00:00, 4.01it/s]
100%|█████████████████████████████████████████████████████████████| 150/150 [00:24<00:00, 6.11it/s]
epoch : 5
training loss: 0.0204, acc 0.8425
validation loss: 0.0121, validation acc 0.9130
torch.save(model.cpu().state_dict(), 'model.pt')
state_dict = torch.load('model.pt')
model.load_state_dict(state_dict)
model.eval();
y_exact, y_pred = [], []
with torch.no_grad():
for val_inputs, val_labels in tqdm(validation_loader, ncols=100):
val_inputs = val_inputs.to(device)
val_labels = val_labels.to(device)
val_outputs = model(val_inputs)
_, val_preds = torch.max(val_outputs, 1)
y_exact += val_labels.tolist()
y_pred += val_preds.tolist()
100%|█████████████████████████████████████████████████████████████| 150/150 [05:12<00:00, 2.08s/it]
len(y_exact), len(y_pred)
(3000, 3000)
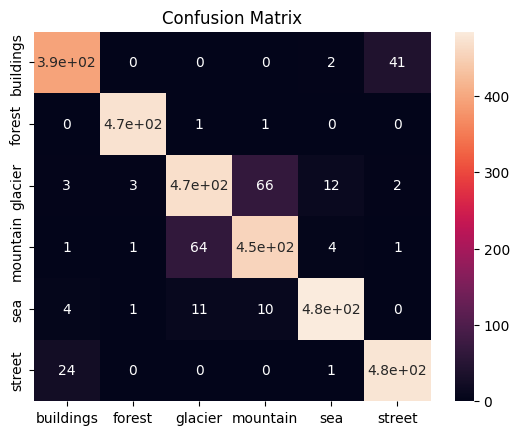
from sklearn.metrics import confusion_matrix
from sklearn import metrics
import seaborn as sns
cnf_matrix = confusion_matrix(y_exact, y_pred)
sns.heatmap(cnf_matrix, annot=True, xticklabels=validation_dataset.classes,
yticklabels=validation_dataset.classes)
plt.title('Confusion Matrix');
orig_validation_dataset = datasets.ImageFolder(dir_test)
def plot_probs(idx, ax):
subset = torch.utils.data.Subset(validation_dataset, [idx])
img, _ = next(iter(torch.utils.data.DataLoader(subset , batch_size=1, shuffle =False)))
preds = model(img)[0]
ax.bar(validation_dataset.classes, preds.detach().numpy())
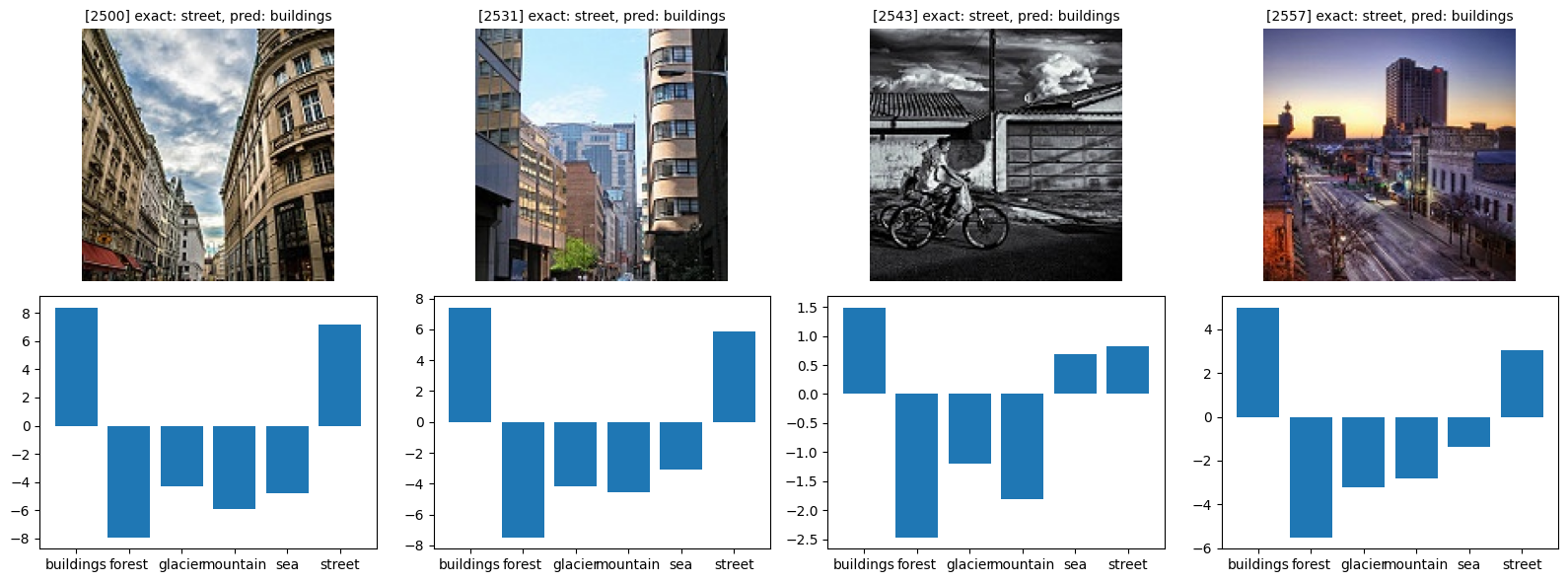
def show_bad(class_idx, start_index=0):
class_name = idx_to_classes[class_idx]
bad = [(i, y_pr) for i, (y_ex, y_pr) in enumerate(zip(y_exact, y_pred)) if y_ex == class_idx and y_ex != y_pr]
fig, axes = plt.subplots(figsize=(16, 6), nrows=2, ncols=4)
for i in range(4):
try:
idx, pred = bad[i + start_index]
img, _ = orig_validation_dataset[idx]
axes[0, i].imshow(img)
axes[0, i].set_title(f'[{idx}] exact: {class_name}, pred: {idx_to_classes[pred]}', fontsize=10)
plot_probs(idx, axes[1, i])
except:
axes[1, i].axis('off')
axes[0, i].axis('off')
fig.tight_layout()
show_bad(0)
show_bad(0, 10)
show_bad(0, 20)
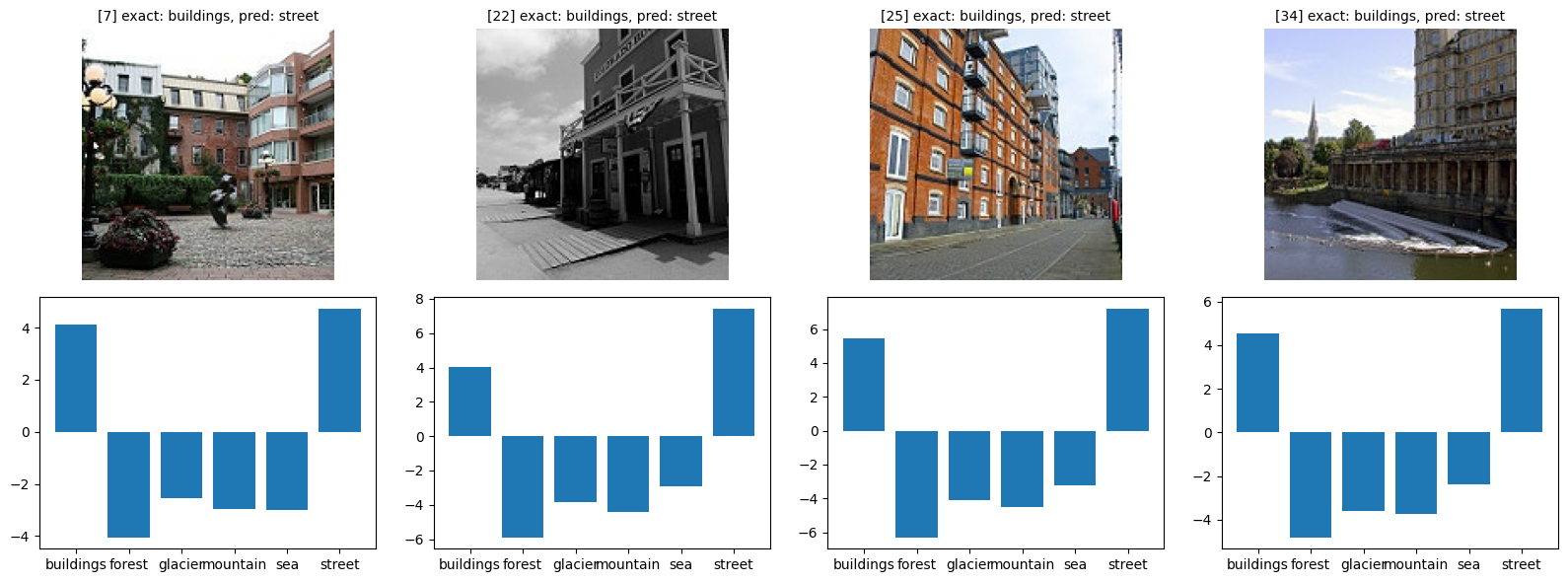
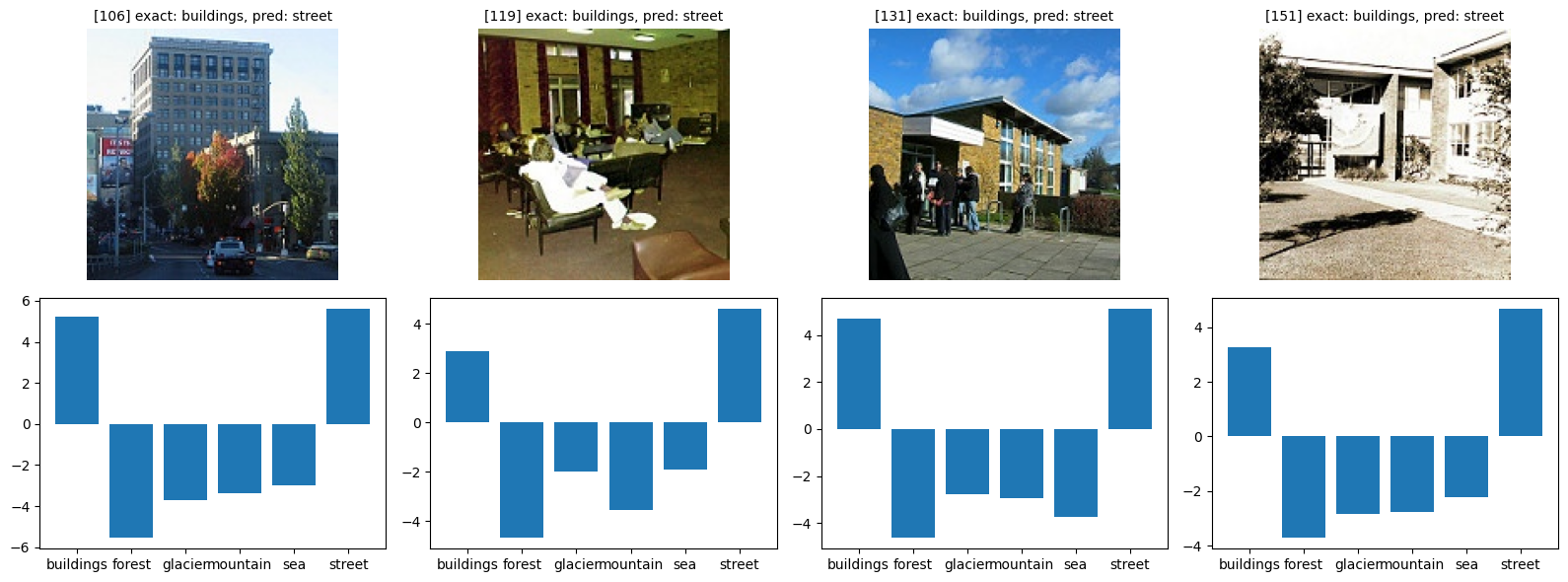
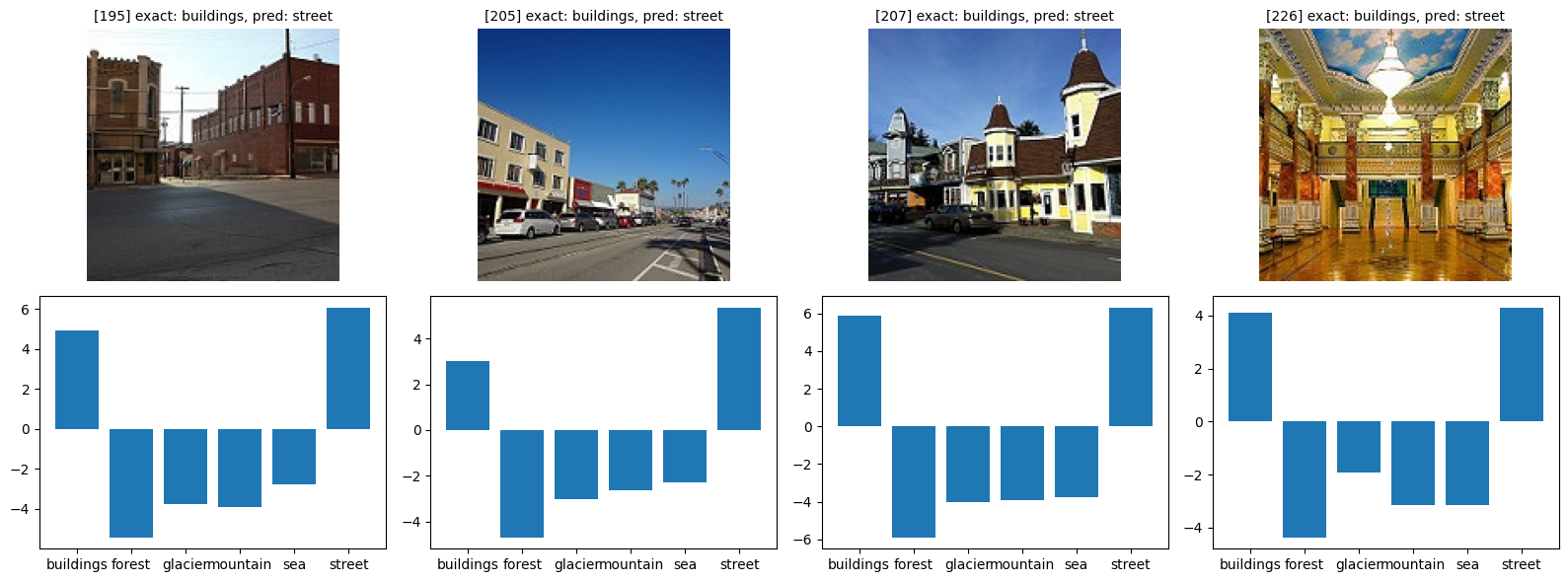
show_bad(1)
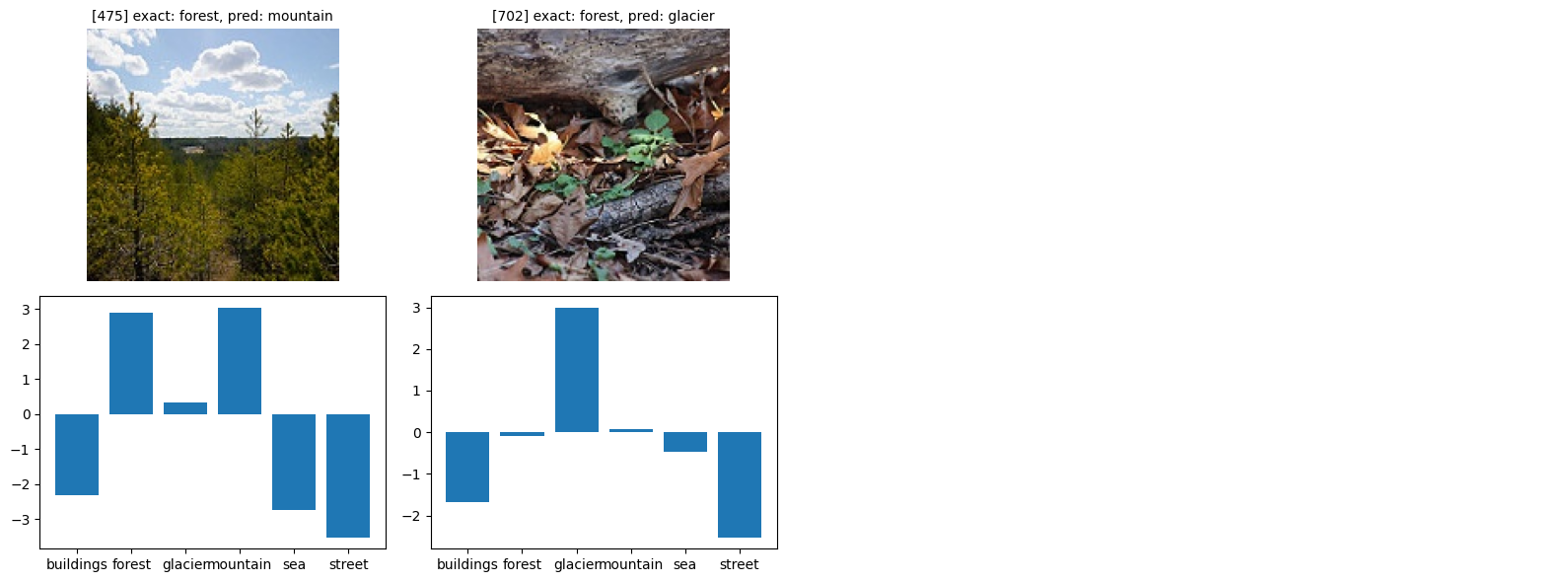
show_bad(2)
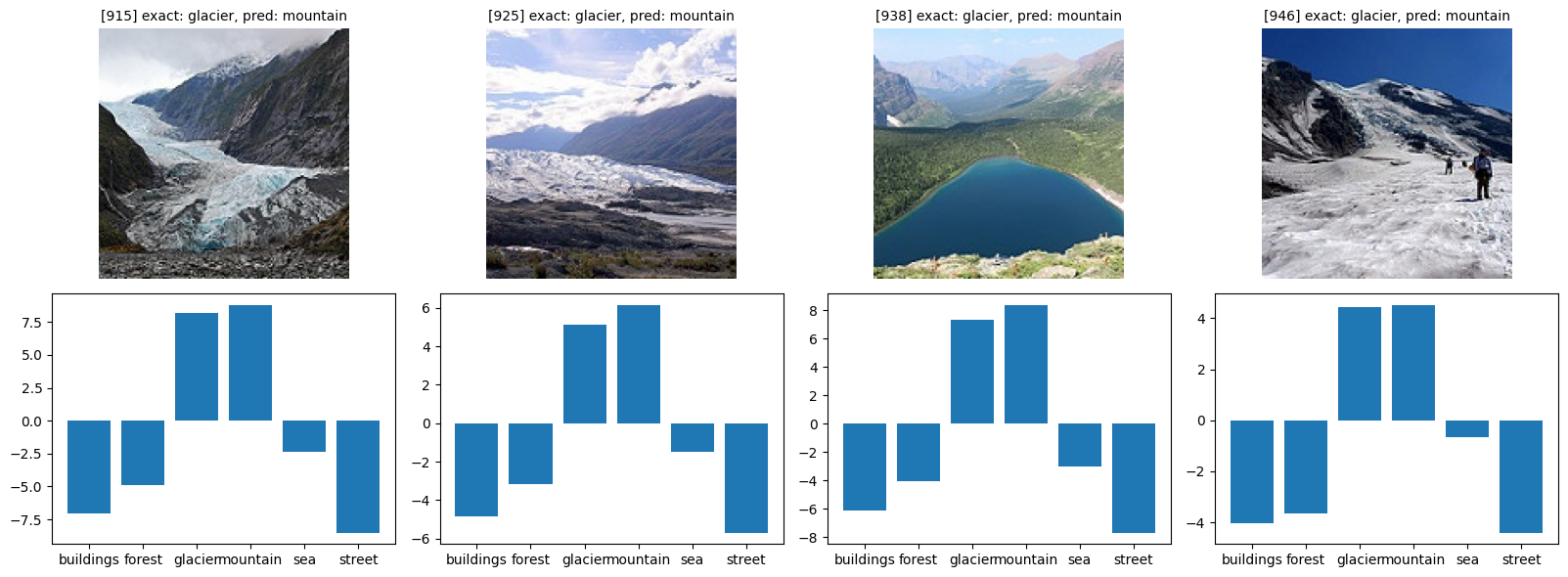
show_bad(3)
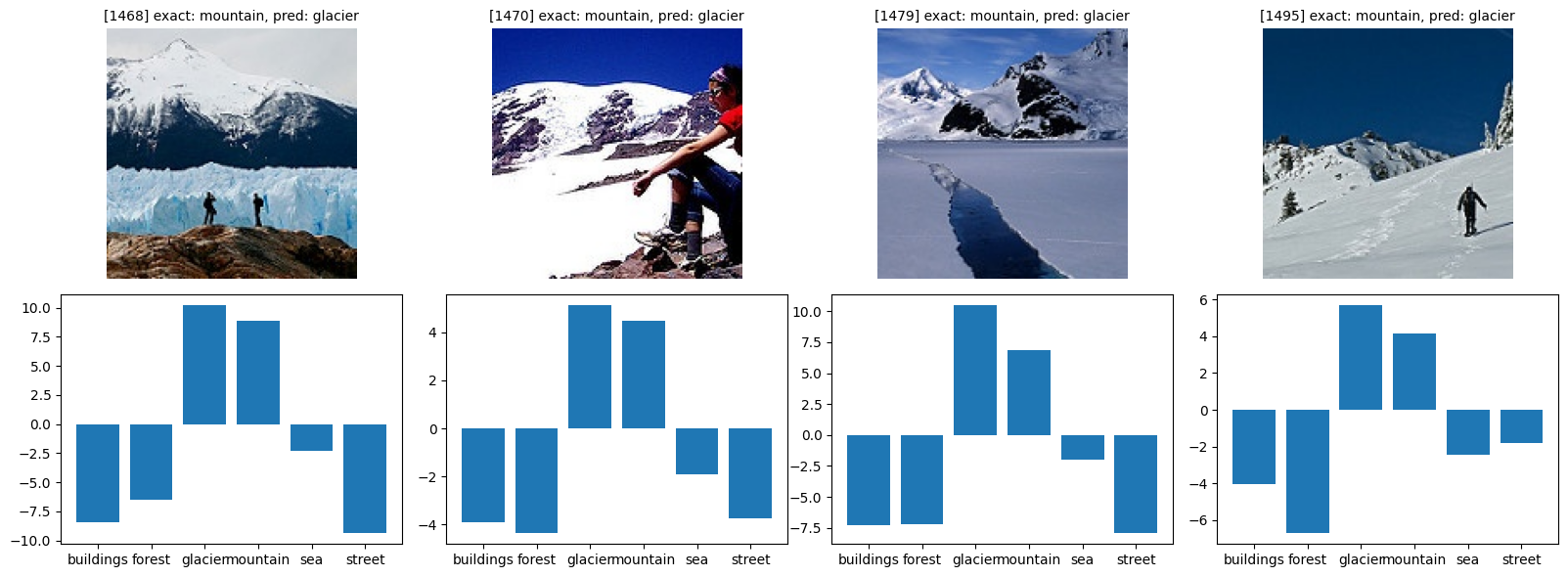
show_bad(4)
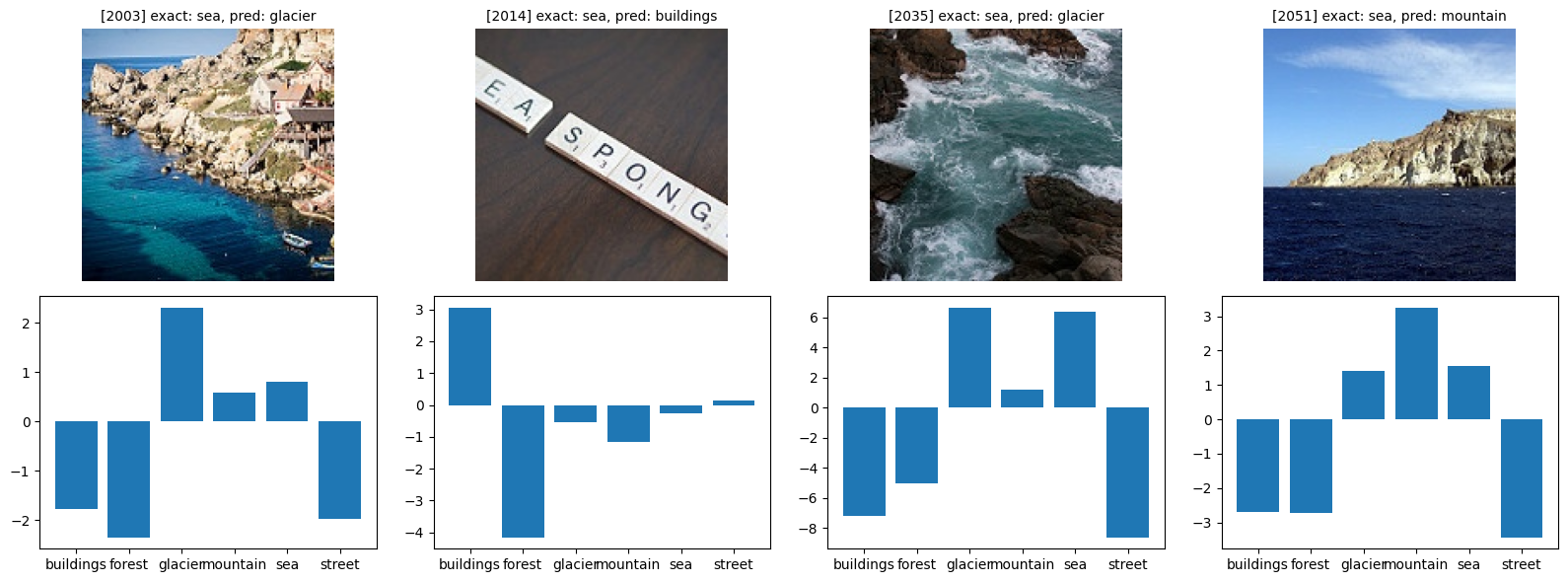
show_bad(5)