conda create --name pendulum python==3.7 --no-default-packages -y
conda activate pendulum
sudo apt-get install xvfb
sudo apt-get install freeglut3-dev
pip install gym[classic_control] torch jupyterlab pyvirtualdisplay matplotlib tensorboard
from typing import Tuple
from collections import deque
import gym
from itertools import count
import matplotlib.pylab as plt
import numpy as np
from pathlib import Path
import os
import platform
import random
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
# we need this to run on a headless server
if platform.system() != 'Windows':
from pyvirtualdisplay import Display
display = Display(visible=0, size=(640, 480)).start()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
class DuelingDeepQNetwork(torch.nn.Module):
def __init__(self, num_inputs, num_actions, num_hidden, name):
super().__init__()
self.name = name
# common part
self.H1 = torch.nn.Linear(num_inputs, num_hidden)
self.H2 = torch.nn.Linear(num_hidden, num_hidden)
# first head, the value
self.V1 = torch.nn.Linear(num_hidden, num_hidden)
self.V2 = torch.nn.Linear(num_hidden, num_hidden)
self.value = torch.nn.Linear(num_hidden, 1)
# second head, the advantage
self.A1 = torch.nn.Linear(num_hidden, num_hidden)
self.A2 = torch.nn.Linear(num_hidden, num_hidden)
self.advantage = torch.nn.Linear(num_hidden, num_actions)
def forward(self, state) -> torch.Tensor:
state = F.relu(self.H1(state))
state = F.relu(self.H2(state))
value = F.relu(self.V1(state))
value = F.relu(self.V2(value))
value = self.value(value)
adv = F.relu(self.A1(state))
adv = F.relu(self.A2(adv))
adv = self.advantage(adv)
return value + adv - torch.mean(adv, dim=-1, keepdim=True)
def pick_action(self, state):
with torch.no_grad():
Q = self.forward(state)
action = torch.argmax(Q, dim=-1)
return action.cpu().numpy()
def save(self, name):
torch.save(self.state_dict(), 'model-'+ name + '.pt')
def load(self, name):
self.load_state_dict(torch.load('model-' + name + '.pt'))
class ReplayMemory:
def __init__(self, capacity):
self.capacity = capacity
self.buffer = []
self.position = 0
def add(self, state, action, reward, next_state, done):
if len(self.buffer) < self.capacity:
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = map(np.stack, zip(*batch))
return state, action, reward, next_state, done
def __len__(self):
return len(self.buffer)
def init_weights(m):
if type(m) == torch.nn.Linear:
torch.nn.init.xavier_uniform_(m.weight)
class Agent():
def __init__(self,
env,
memory_size,
batch_size,
learning_rate: float = 0.5e-4,
gamma: float = 0.99,
epsilon: float = 1.0,
eps_min: float = 0.01,
eps_dec: float = 1e-3,
tau: float = 0.001,
training: bool = True):
self.env = env
self.gamma = gamma
self.epsilon = epsilon
self.lr = learning_rate
self.action_dim = env.action_space.n
self.input_dim = env.observation_space.shape[0]
self.batch_size = batch_size
self.eps_min = eps_min
self.eps_dec = eps_dec
self.tau = tau
self.training = training
self.memory = ReplayMemory(memory_size)
self.online_network = DuelingDeepQNetwork(num_inputs=self.input_dim,
num_actions=self.action_dim,
num_hidden=128,
name='OnlinePolicy')
self.online_network.apply(init_weights)
self.optimizer = optim.Adam(self.online_network.parameters(), lr=learning_rate)
self.target_network = DuelingDeepQNetwork(num_inputs=self.input_dim,
num_actions=self.action_dim,
num_hidden=128,
name='TargetPolicy')
self.target_network.apply(init_weights)
self.update_networks(tau=1.0)
def choose_action(self, observation) -> int:
if self.training:
if np.random.rand(1) > self.epsilon:
self.online_network.eval()
state = torch.as_tensor(observation, dtype=torch.float32, device=device)
with torch.no_grad():
action = self.online_network.pick_action(state)
else:
action = self.env.action_space.sample()
return action
else:
state = torch.as_tensor(observation, dtype=torch.float32, device=device)
with torch.no_grad():
return self.online_network.pick_action(state)
def store_transition(self, state, action, reward, next_state, done):
self.memory.add(state, action, reward, next_state, done)
def update_networks(self, tau) -> None:
for online_weights, target_weights in zip(self.online_network.parameters(), self.target_network.parameters()):
target_weights.data.copy_(tau * online_weights.data + (1 - tau) * target_weights.data)
def epsilon_update(self) -> None:
'''Decrease epsilon iteratively'''
if self.epsilon > self.eps_min:
self.epsilon -= self.eps_dec
def save_models(self) -> None:
self.online_network.save()
self.target_network.save()
def load_models(self) -> None:
self.online_network.load()
self.target_network.load()
def optimize(self):
if self.memory.__len__() < self.batch_size:
return
states, actions, rewards, next_states, dones = self.memory.sample(self.batch_size)
states = torch.as_tensor(np.vstack(states), dtype=torch.float32, device=device)
rewards = torch.as_tensor(np.vstack(rewards), dtype=torch.float32, device=device)
dones = torch.as_tensor(np.vstack(dones), dtype=torch.float32, device=device)
actions = torch.as_tensor(np.vstack(actions), dtype=torch.float32, device=device)
next_states = torch.as_tensor(np.vstack(next_states), dtype=torch.float32, device=device)
self.online_network.train()
self.target_network.train()
with torch.no_grad():
next_q_values = self.target_network(next_states)
next_q_values, _ = next_q_values.max(dim=1)
next_q_values = next_q_values.reshape(-1, 1)
target_q_values = rewards + (1 - dones) * self.gamma * next_q_values
current_q_values = self.online_network(states)
current_q_values = torch.gather(current_q_values, dim=1, index=actions.long())
# Compute Huber loss (less sensitive to outliers)
loss = F.huber_loss(current_q_values, target_q_values)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.update_networks(tau=self.tau)
writer = SummaryWriter(log_dir=os.path.abspath('tensorboard'))
ENV_NAME = 'MountainCar-v0'
NUM_EPISODES = 5_000
MEMORY_SIZE = 1_000
BATCH_SIZE = 64
LEARNING_RATE = 1e-3
SEED = 42
env = gym.make(ENV_NAME)
env.reset()
total_rewards, averages = [], []
random.seed(SEED)
torch.manual_seed(SEED)
agent = Agent(env=env, memory_size=MEMORY_SIZE * env._max_episode_steps,
batch_size=BATCH_SIZE, learning_rate=LEARNING_RATE, eps_dec=0.01, eps_min=0.01)
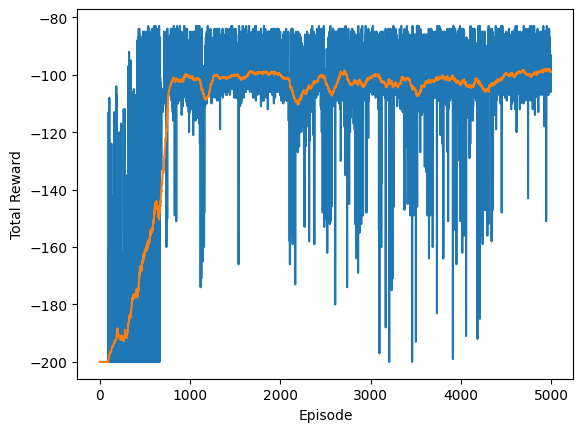
for i in range(NUM_EPISODES):
total_reward = 0.0
state, _ = env.reset()
for t in count():
action = agent.choose_action(state)
next_state, reward, done, truncated, _ = env.step(action)
agent.memory.add(state, action, reward, next_state, done or truncated)
state = next_state
total_reward += reward
agent.optimize()
if done or truncated:
agent.epsilon_update()
break
total_rewards.append(total_reward)
average = np.mean(total_rewards[-100:])
averages.append(average)
#print(f'episode: {i}, total reward: {total_reward:.3f}, average: {average:.3f}, {agent.epsilon:.3f}', end='\r')
agent.save_models()
writer.close()
plt.plot(total_rewards)
plt.plot(averages)
plt.xlabel('Episode')
plt.ylabel('Total Reward');
test_env = gym.make('MountainCar-v0', render_mode='rgb_array')
agent.training = False
rewards = [0.0]
state, _ = test_env.reset()
frames = [test_env.render()]
done = False
state, _ = test_env.reset()
while not done:
action = agent.choose_action(state)
next_state, reward, done, truncated, _ = test_env.step(action)
frames.append(test_env.render())
if truncated: done = True
state = next_state
rewards.append(reward)
test_env.close()
total_rewards = [0] + np.cumsum(rewards).tolist()
# np array with shape (frames, height, width, channels)
video = np.array(frames[:])
fig, ax = plt.subplots(figsize=(4, 4))
im = ax.imshow(video[0,:,:,:])
ax.set_axis_off()
text = ax.text(30, 60, '', color='red')
plt.close() # this is required to not display the generated image
def init():
im.set_data(video[0,:,:,:])
def animate(i):
im.set_data(video[i,:,:,:])
text.set_text(f'Step {i}, total reward: {total_rewards[i]:.2f}')
return im
from matplotlib import animation
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=video.shape[0],
interval=100)
anim.save('mountain-car-video.gif', writer='pillow', dpi=80, fps=24)

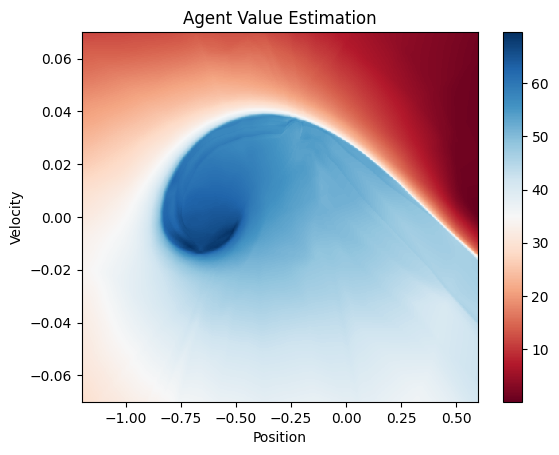
def predict_value(agent: Agent, state: np.ndarray) -> float:
state = torch.as_tensor([state], dtype=torch.float32)
value = agent.online_network(state).detach().numpy()
return -np.max(value)
x = np.linspace(env.observation_space.low[0], env.observation_space.high[0], num=500)
y = np.linspace(env.observation_space.low[1], env.observation_space.high[1], num=500)
x, y = np.meshgrid(x, y)
z = np.apply_along_axis(lambda _: predict_value(agent, _), 2, np.dstack([x, y]))
z = z[:-1, :-1]
z_min, z_max = z.min(), z.max()
fig, ax = plt.subplots()
ax.pcolormesh(x, y, z, cmap='RdBu', vmin=z_min, vmax=z_max)
ax.axis([x.min(), x.max(), y.min(), y.max()])
ax.set_xlabel('Position')
ax.set_ylabel('Velocity')
ax.set_title("Agent Value Estimation")
fig.colorbar(ax.pcolormesh(x, y, z, cmap='RdBu', vmin=z_min, vmax=z_max));