The computations are run on an Ubuntu Linux computer, with the following conda environment:
conda create --name mountain-car-continuous python==3.7 --no-default-packages -y
conda activate mountain-car-continuous
pip install gym[classic_control]
sudo apt-get install xvfb
pip install jupyterlab
pip install pyvirtualdisplay
pip install matplotlib
pip install cma
pip install scipy
import os
import numpy as np
import gym
import cma
from copy import copy
import concurrent.futures
import matplotlib.pylab as plt
from matplotlib import animation
from itertools import product
import argparse
import pickle
env = gym.make('MountainCarContinuous-v0', render_mode='rgb_array')
state = env.reset()
np.random.seed(0)
state_shape = env.observation_space.shape[0]
action_shape = env.action_space.shape[0]
N_HIDDEN_1 = 25
POPULATION_SIZE = 16
def reshape(theta, state_shape, action_shape):
w1_length = state_shape * N_HIDDEN_1
b1_length = N_HIDDEN_1
w2_length = N_HIDDEN_1 * action_shape
b2_length = action_shape
w1_theta = np.copy(theta[0:w1_length])
b1_theta = np.copy(theta[w1_length:w1_length+b1_length])
w2_theta = np.copy(theta[w1_length+b1_length:w1_length+b1_length+w2_length])
b2_theta = np.copy(theta[-b2_length:].copy())
w1_theta = np.reshape(w1_theta, (state_shape, N_HIDDEN_1))
b1_theta = np.reshape(b1_theta, (N_HIDDEN_1,))
w2_theta = np.reshape(w2_theta, (N_HIDDEN_1, action_shape))
b2_theta = np.reshape(b2_theta, (action_shape,))
return (w1_theta, b1_theta, w2_theta, b2_theta)
def play_episode(theta, render=False):
theta = reshape(np.copy(theta), state_shape, action_shape)
rewards = [0.0]
state, _ = env.reset()
frames = [env.render()] if render else None
done = False
while not done:
state = np.squeeze(state)
h1 = np.matmul(np.expand_dims(state, axis=0), theta[0]) + theta[1]
action = np.tanh(np.matmul(h1, theta[2]) + theta[3])
next_state, reward, done, terminated, _ = env.step(action)
if terminated: done = True
if render:
frames.append(env.render())
rewards.append(reward)
state = next_state
# avoid episodes too long
if len(rewards) > 1000:
break
return rewards, frames
N_THETA = state_shape * N_HIDDEN_1 + N_HIDDEN_1 + N_HIDDEN_1 * action_shape + action_shape
print(f"# CPUs: {os.cpu_count()}, # parameters: {N_THETA}, population size: {POPULATION_SIZE}")
# CPUs: 8, # parameters: 101, population size: 16
es = cma.CMAEvolutionStrategy(N_THETA * [0], 0.5, {'popsize': POPULATION_SIZE, 'seed': 42})
history = []
for i in range(2_000):
solutions = es.ask()
outputs = list(map(play_episode, solutions))
# we minimize, not maximize
total_rewards = -np.array(list(map(lambda x: sum(x[0]), outputs)))
es.tell(solutions, total_rewards)
history.append(total_rewards)
# print(f'\tMin: {total_rewards.min()}, max; {total_rewards.max()}, mean: {total_rewards.mean()}')
es.disp()
env.close()
(8_w,16)-aCMA-ES (mu_w=4.8,w_1=32%) in dimension 101 (seed=42, Thu Sep 29 19:49:49 2022)
/opt/conda/envs/mountain-car-continuous/lib/python3.7/site-packages/gym/utils/passive_env_checker.py:165: UserWarning: [33mWARN: The obs returned by the `step()` method is not within the observation space.[0m
logger.warn(f"{pre} is not within the observation space.")
Iterat #Fevals function value axis ratio sigma min&max std t[m:s]
1 16 1.502839754904724e+00 1.0e+00 4.81e-01 5e-01 5e-01 0:00.6
2 32 -6.646012667324604e+01 1.0e+00 4.67e-01 5e-01 5e-01 0:01.3
3 48 -5.465133991109310e+01 1.0e+00 4.55e-01 5e-01 5e-01 0:02.0
8 128 -3.068559179630321e+01 1.0e+00 4.25e-01 4e-01 4e-01 0:05.2
15 240 -9.552544701060445e+01 1.1e+00 4.19e-01 4e-01 4e-01 0:09.6
/opt/conda/envs/mountain-car-continuous/lib/python3.7/site-packages/gym/envs/classic_control/continuous_mountain_car.py:171: DeprecationWarning: setting an array element with a sequence. This was supported in some cases where the elements are arrays with a single element. For example `np.array([1, np.array([2])], dtype=int)`. In the future this will raise the same ValueError as `np.array([1, [2]], dtype=int)`.
self.state = np.array([position, velocity], dtype=np.float32)
24 384 -8.786137542985512e+01 1.1e+00 4.20e-01 4e-01 4e-01 0:14.8
35 560 -9.520639168347108e+01 1.2e+00 4.28e-01 4e-01 4e-01 0:20.9
48 768 -7.462872998594121e+01 1.2e+00 4.24e-01 4e-01 4e-01 0:28.1
64 1024 -9.345241306785253e+01 1.3e+00 4.42e-01 4e-01 5e-01 0:36.2
83 1328 -8.912790851050210e+01 1.4e+00 5.09e-01 5e-01 5e-01 0:45.7
100 1600 -8.998464581098267e+01 1.4e+00 4.85e-01 5e-01 5e-01 0:54.2
123 1968 -9.253289330772405e+01 1.5e+00 4.22e-01 4e-01 4e-01 1:05.2
149 2384 -9.160463847218981e+01 1.5e+00 4.07e-01 4e-01 4e-01 1:17.3
181 2896 -9.451325729414420e+01 1.6e+00 4.58e-01 4e-01 5e-01 1:30.3
200 3200 -9.074752236387545e+01 1.6e+00 4.50e-01 4e-01 5e-01 1:37.1
243 3888 -9.315807137483985e+01 1.7e+00 4.48e-01 4e-01 5e-01 1:52.4
283 4528 -9.335987300123774e+01 1.8e+00 4.44e-01 4e-01 5e-01 2:08.5
300 4800 -9.257067658096769e+01 1.8e+00 4.47e-01 4e-01 5e-01 2:13.6
358 5728 -9.317723918847366e+01 1.9e+00 3.98e-01 4e-01 4e-01 2:31.7
400 6400 -9.257488748293781e+01 2.0e+00 3.60e-01 3e-01 4e-01 2:45.3
483 7728 -9.353893549681915e+01 2.1e+00 3.07e-01 3e-01 3e-01 3:05.4
500 8000 -9.328339664349933e+01 2.1e+00 3.16e-01 3e-01 3e-01 3:08.9
597 9552 -9.351628460627350e+01 2.3e+00 3.24e-01 3e-01 3e-01 3:31.0
600 9600 -9.300784346591743e+01 2.3e+00 3.27e-01 3e-01 3e-01 3:31.6
690 11040 -9.281270587728579e+01 2.4e+00 3.60e-01 3e-01 4e-01 3:55.8
700 11200 -9.137431534209358e+01 2.4e+00 3.59e-01 3e-01 4e-01 3:58.6
800 12800 -9.257380300057699e+01 2.6e+00 2.82e-01 3e-01 3e-01 4:22.8
900 14400 -9.352347228619102e+01 2.7e+00 2.73e-01 3e-01 3e-01 4:41.8
1000 16000 -9.349452192157889e+01 2.8e+00 2.07e-01 2e-01 2e-01 4:56.9
Iterat #Fevals function value axis ratio sigma min&max std t[m:s]
1100 17600 -9.345542787490389e+01 3.0e+00 1.91e-01 2e-01 2e-01 5:09.7
1200 19200 -9.336087239567482e+01 3.1e+00 2.04e-01 2e-01 2e-01 5:21.2
1300 20800 -9.327746855232169e+01 3.3e+00 1.93e-01 2e-01 2e-01 5:32.0
1400 22400 -9.381875731368403e+01 3.5e+00 1.87e-01 2e-01 2e-01 5:42.9
1500 24000 -9.344324633721889e+01 3.6e+00 1.76e-01 2e-01 2e-01 5:53.4
1600 25600 -9.358110100892283e+01 3.9e+00 1.68e-01 2e-01 2e-01 6:03.9
1700 27200 -9.338956351808618e+01 4.0e+00 1.78e-01 2e-01 2e-01 6:14.9
1800 28800 -9.381769311707737e+01 4.2e+00 1.62e-01 1e-01 2e-01 6:25.4
1900 30400 -9.364299196548910e+01 4.4e+00 1.98e-01 2e-01 2e-01 6:35.9
2000 32000 -9.349874932676293e+01 4.6e+00 2.02e-01 2e-01 2e-01 6:46.3
history = -np.array(history)
def smooth(x,window_len=11,window='hanning'):
s =np.r_[x[window_len-1:0:-1],x,x[-2:-window_len-1:-1]]
#print(len(s))
if window == 'flat': #moving average
w=np.ones(window_len,'d')
else:
w=eval('np.'+window+'(window_len)')
y=np.convolve(w/w.sum(),s,mode='valid')
return y
from scipy.signal import butter, filtfilt
plt.figure(figsize=(12, 4))
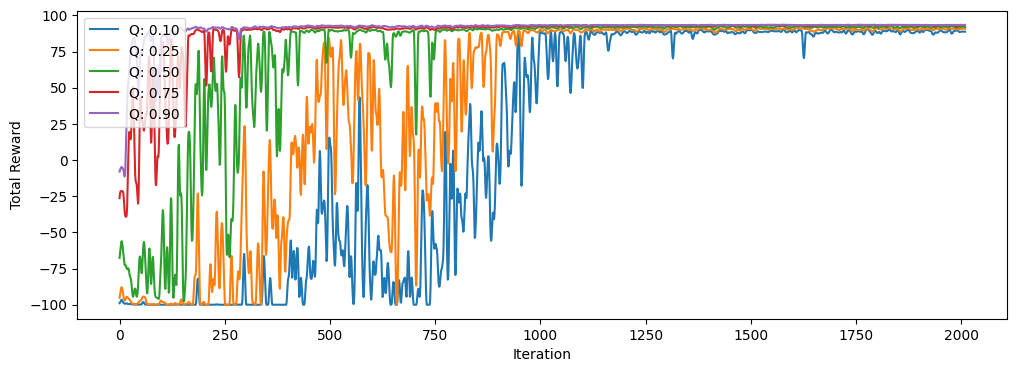
for q in [0.1, 0.25, 0.5, 0.75, 0.9]:
line = np.quantile(history, q, axis=1)
plt.plot(smooth(line), label=f'Q: {q:.2f}')
plt.xlabel('Iteration')
plt.ylabel('Total Reward')
plt.legend(loc='upper left');
rewards, frames = play_episode(es.result.xbest, render=True)
total_rewards = [0] + np.cumsum(rewards).tolist()
# np array with shape (frames, height, width, channels)
video = np.array(frames[:])
fig, ax = plt.subplots(figsize=(4, 4))
im = ax.imshow(video[0,:,:,:])
ax.set_axis_off()
text = ax.text(30, 60, '', color='red')
plt.close() # this is required to not display the generated image
def init():
im.set_data(video[0,:,:,:])
def animate(i):
im.set_data(video[i,:,:,:])
text.set_text(f'Step {i}, total reward: {total_rewards[i]:.2f}')
return im
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=video.shape[0],
interval=100)
anim.save('mountain-car-continuous-video.gif', writer='pillow', dpi=80, fps=24)
