https://www.omniglot.com/
from collections import defaultdict
import cv2
import matplotlib.pylab as plt
import numpy as np
from pathlib import Path
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.has_mps:
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using device {device}.")
Using device cpu.
A version of this dataset is readily available from PyTorch and it appears to contain 964 labels only.
dataset = dset.Omniglot('./data', download=True)
label_to_image = defaultdict(lambda: [])
for image, label in dataset:
label_to_image[label].append(image)
print(f"Dataset contains {len(dataset)} entries and {len(set(label_to_image))} labels.")
Files already downloaded and verified
Dataset contains 19280 entries and 964 labels.
Each letter is present twenty times – we plot a few of them, with each of the twenty realizations filling a column, with a different letter on each column.
n = 40
fig, axes = plt.subplots(nrows=20, ncols=n, figsize=(20, 10), sharex=True, sharey=True)
for j in range(n):
for i in range(20):
axes[i, j].imshow(label_to_image[j][i], cmap='Greys_r')
axes[i, j].axis('off')
axes[0, j].set_title(j, color='red')
plt.imshow(dataset[0][0], cmap='Greys_r')
<matplotlib.image.AxesImage at 0x297dbfee0>

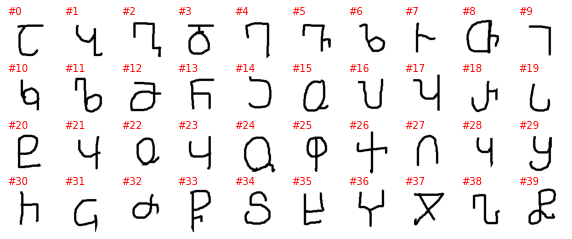
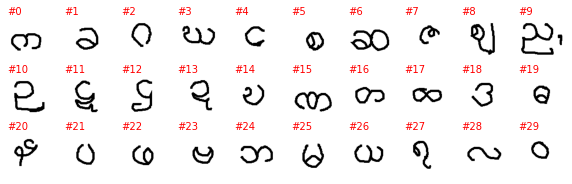
The labels as provided by PyTorch are a number with no connection to the alphabet and the letter it represents (or at least I can’t figure it out), so the plot above is not very informative. To better understand this dataset we need to go into the directory with the downloaded data and explore it manually. The directory contains 30 subdirectories, one per alphabet, and without each of the 30 directories we have as many subdirectories as letters in the alphabet. Unfortunately, the letter it represents is not explicitly show and must be guesses, even if it is often easy to do so.
base_dir = Path('./data/omniglot-py/images_background')
alphabets = []
for item in sorted(base_dir.glob('*')):
if item.is_dir():
alphabets.append(item)
print(f"Found {len(alphabets)} alphabets.")
num_alphabets = len(alphabets)
Found 30 alphabets.
for alphabet in alphabets:
print(alphabet.stem)
samples = []
for c in list(alphabet.glob('character*')):
samples.append(cv2.imread(str(next(c.glob('*.png')))))
nrows = len(samples) // 10
fig, axes = plt.subplots(figsize=(10, 1 * nrows), nrows=nrows, ncols=10)
axes = axes.flatten()
for ax in axes: ax.axis('off')
for i, (ax, sample) in enumerate(zip(axes, samples)):
ax.text(0, 0, f'#{i}', color='red')
ax.imshow(sample)
plt.show()
Alphabet_of_the_Magi

Anglo-Saxon_Futhorc

Arcadian

Armenian
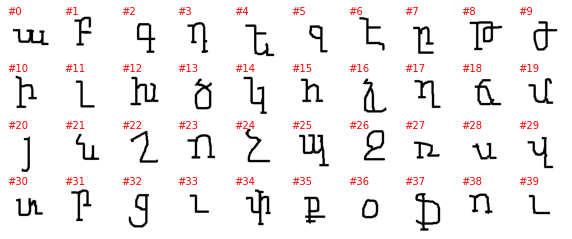
Asomtavruli_(Georgian)
Balinese

Bengali

Blackfoot_(Canadian_Aboriginal_Syllabics)

Braille
Burmese_(Myanmar)
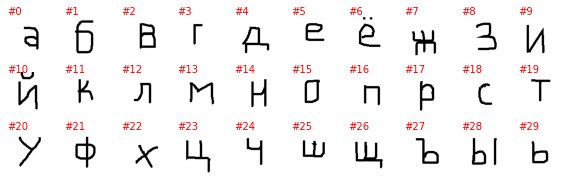
Cyrillic
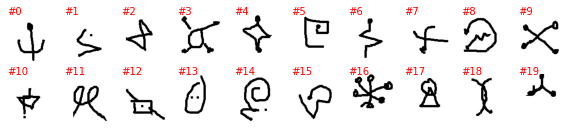
Early_Aramaic

Futurama
Grantha

Greek

Gujarati

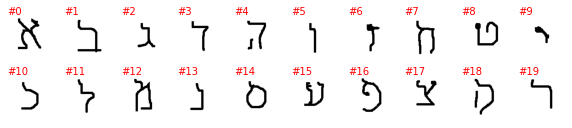
Hebrew
Inuktitut_(Canadian_Aboriginal_Syllabics)
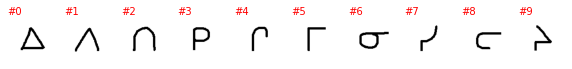
Japanese_(hiragana)

Japanese_(katakana)

Korean

Latin

Malay_(Jawi_-_Arabic)
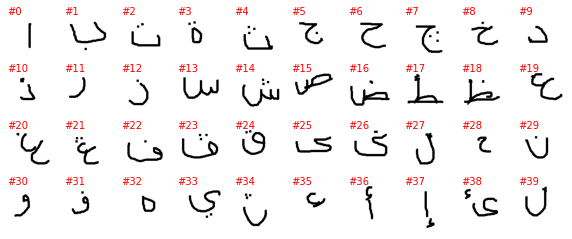
Mkhedruli_(Georgian)

N_Ko
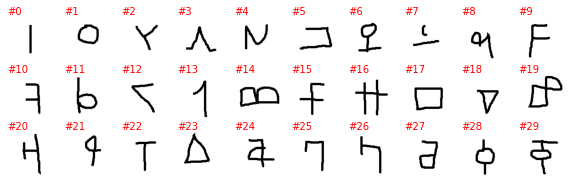
Ojibwe_(Canadian_Aboriginal_Syllabics)
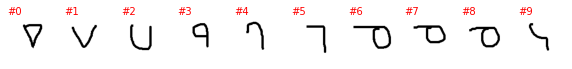
Sanskrit

Syriac_(Estrangelo)
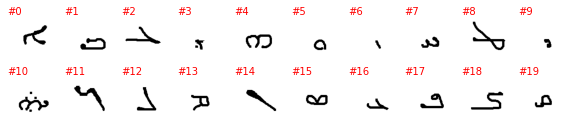
Tagalog

Tifinagh
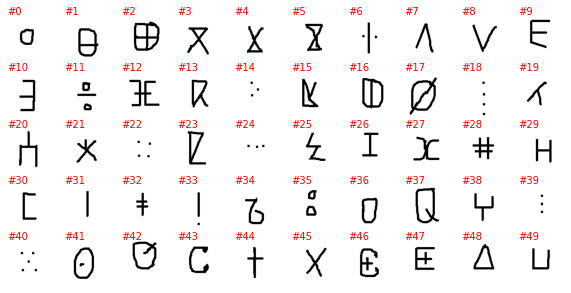
class OmniglotData:
def __init__(self):
from PIL import Image
self.images, self.labels = [], []
for alphabet in sorted(base_dir.glob('*')):
if not alphabet.is_dir():
continue
for c in list(alphabet.glob('character*')):
for img in c.glob('*.png'):
self.images.append(Image.fromarray(cv2.imread(str(img))))
self.labels.append(alphabet.stem)
assert len(self.images) == len(self.labels)
print(f"Found {len(self.images)} images.")
class OmniglotDataset(torch.utils.data.Dataset):
def __init__(self, images, labels, transform=None):
self.images = images
self.labels = labels
self.transform = transform
tmp = sorted(set(labels))
self.label_to_idx = {label: i for i, label in enumerate(tmp)}
self.idx_to_label = {i: label for i, label in enumerate(tmp)}
def __len__(self):
return len(self.images)
def __getitem__(self, i):
image, label = self.images[i], self.labels[i]
if self.transform is not None:
image = self.transform(image)
return image, self.label_to_idx[label]
IMAGE_SIZE = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(IMAGE_SIZE + 4, antialias=True),
transforms.Grayscale(),
transforms.RandomRotation((-10, 10)),
transforms.RandomCrop(IMAGE_SIZE),
transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.2, 0.2)),
transforms.Normalize((0.,), (1.0,)),
])
dataset = OmniglotDataset(images, labels, transform)
manual_seed = 42
random.seed(manual_seed)
torch.manual_seed(manual_seed);
BATCH_SIZE = 128
dataset_train, dataset_test = torch.utils.data.random_split(dataset, [0.8, 0.2])
data_loader_train = torch.utils.data.DataLoader(dataset=dataset_train, batch_size=BATCH_SIZE, shuffle=True)
data_loader_test = torch.utils.data.DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=False)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Linear') != -1:
torch.nn.init.normal_(m.weight, 0.0, 0.02)
torch.nn.init.zeros_(m.bias)
class Classifier(nn.Module):
def __init__(self, num_hidden, num_classes):
super().__init__()
self.main = nn.Sequential(
nn.Conv2d(1, num_hidden, 4, 2, 1),
nn.Conv2d(num_hidden, num_hidden * 2, 4, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_hidden * 2, num_hidden * 4, 4, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_hidden * 4, num_hidden * 8, 4, 2, 1),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(1, -1),
nn.Linear(4096, num_classes),
)
def forward(self, input):
return self.main(input)
classifier = Classifier(num_hidden=32, num_classes=num_alphabets).to(device)
classifier.apply(weights_init)
Classifier(
(main): Sequential(
(0): Conv2d(1, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(2): LeakyReLU(negative_slope=0.2, inplace=True)
(3): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(6): LeakyReLU(negative_slope=0.2, inplace=True)
(7): Flatten(start_dim=1, end_dim=-1)
(8): Linear(in_features=4096, out_features=30, bias=True)
)
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(classifier.parameters(), lr=0.001)
for epoch in range(10):
total_loss_train, total_accuracy_train = 0.0, 0.0
for inputs, labels in data_loader_train:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = classifier(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss_train += loss.item()
_, preds = torch.max(outputs, 1)
total_accuracy_train += torch.sum(preds == labels.data).item()
total_loss_test, total_accuracy_test = 0.0, 0.0
with torch.no_grad():
for inputs, labels in data_loader_test:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = classifier(inputs)
loss = criterion(outputs, labels)
total_loss_test += loss.item()
_, preds = torch.max(outputs, 1)
total_accuracy_test += torch.sum(preds == labels.data).item()
total_loss_train /= len(dataset_train)
total_loss_test /= len(dataset_test)
total_accuracy_train /= len(dataset_train)
total_accuracy_test /= len(dataset_test)
print(f'epoch {epoch + 1: 3d}, loss: {total_loss_train:.5f} vs. {total_loss_test:.5f}, '\
f' accuracy: {total_accuracy_train:.4%} vs. {total_accuracy_test:.4%}')
running_loss = 0.0
epoch 1, loss: 0.02201 vs. 0.01855, accuracy: 20.7534% vs. 33.9471%
epoch 2, loss: 0.01585 vs. 0.01427, accuracy: 40.3203% vs. 48.1068%
epoch 3, loss: 0.01321 vs. 0.01235, accuracy: 49.9416% vs. 54.5124%
epoch 4, loss: 0.01127 vs. 0.01152, accuracy: 56.1657% vs. 56.6131%
epoch 5, loss: 0.00990 vs. 0.01024, accuracy: 61.0737% vs. 61.5145%
epoch 6, loss: 0.00905 vs. 0.01000, accuracy: 64.3024% vs. 61.9813%
epoch 7, loss: 0.00821 vs. 0.00961, accuracy: 66.9282% vs. 64.0560%
epoch 8, loss: 0.00750 vs. 0.00938, accuracy: 70.0726% vs. 64.5747%
epoch 9, loss: 0.00692 vs. 0.00894, accuracy: 72.6336% vs. 67.6608%
epoch 10, loss: 0.00661 vs. 0.00830, accuracy: 73.1198% vs. 69.4761%
torch.save(classifier.state_dict(), "./classifier.pt")