In this article we use large language models (LLMs) to compute the sentiment analysis of news titles. We use mediastack to get the list of news and OpenAI for the sentiment analysis. Mediastack requires a key; the free service will suffice. We focus on news from Great Britain; of each news, we take into consideration the title and the description.
with open('mediastack-key.txt', 'r') as f:
mediastack_key = f.read()
import http.client, urllib.parse
conn = http.client.HTTPConnection('api.mediastack.com')
items = []
for i in range(10):
params = urllib.parse.urlencode({
'access_key': mediastack_key,
'countries': 'gb',
'sort': 'published_desc',
'sources': 'bbc',
'limit': 100,
'offset': 100 * i,
})
conn.request('GET', '/v1/news?{}'.format(params))
res = conn.getresponse()
data = res.read()
import json
news = json.loads(data.decode('utf-8'))
assert news['pagination']['offset'] == 100 * i
items += news['data']
import pandas as pd
df = pd.DataFrame.from_dict(items)
with open('open-ai-key.txt', 'r') as f:
openai_api_key = f.read()
It is convenient to use frameworks like langchain instead of rolling our own version. We ask for the sentiment, in a scale from -2 to 2, but also the topic, to be selected from a given list, and the location, to be selected as well from a list; in addition we request the reasoning that has been applied.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-3.5-turbo-1106', temperature=0.1, openai_api_key=openai_api_key)
description = f"""
You are asked to perform sentiment analysis on the following news header from the BBC website, \
with the higher the number the more positive the sentiment
""".strip()
schema = {
'properties': {
'sentiment': {
'type': 'integer',
'enum': [-2, -1, 0, 1, 2],
'description': description,
},
'topic': {
'type': 'string',
'enum': ['business', 'entertainement', 'politics', 'education', 'sports', 'technology', 'health'],
'description': "You are asked to classify the topic to which the news header refers to",
},
'location': {
'type': 'string',
'enum': ['local', 'state', 'continent', 'world'],
'description': "You are asked to classify the region of interest of the news header",
},
'reasoning':{
'type':'string',
'description': '''Explain, in a concise way, why you gave that particular tag to the news. If you can't complete the request, say why.'''
}
},
'required':['sentiment', 'topic', 'location', 'reasoning']
}
from langchain.chains import create_tagging_chain
chain = create_tagging_chain(schema=schema, llm=llm)
def tagger(row):
try:
text = row.title + '. ' + row.description
sentiment = chain.invoke(text)
return sentiment['text']['sentiment'], sentiment['text']['topic'], sentiment['text']['location'], sentiment['text']['reasoning']
except Exception as e:
print(text, e)
return 'Failed request: ' + str(e)
tags = df.apply(tagger, result_type='expand', axis=1)
tags
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -2 | sports | local | The news headline is about a local sports even... |
| 1 | 2 | sports | local | The news headline refers to a local sports eve... |
| 2 | -2 | education | local | The news header mentions a local incident in F... |
| 3 | -1 | entertainment | local | The news is related to the entertainment indus... |
| 4 | -2 | sports | local | The news refers to a local sports event in Bri... |
| ... | ... | ... | ... | ... |
| 995 | 2 | politics | world | The news refers to Ukraine's president Zelensk... |
| 996 | -2 | health | local | The passage is about a local health issue, spe... |
| 997 | 2 | politics | local | The news header refers to a local political ev... |
| 998 | 0 | technology | world | The passage discusses the alteration of a phot... |
| 999 | -2 | politics | local | The passage contains political news, specifica... |
1000 rows × 4 columns
tags.columns = ['pred_sentiment', 'pred_topic', 'pred_location', 'pred_reason']
results = pd.concat([df, tags], axis=1)
results = results[['title', 'description', 'url', 'category', 'pred_sentiment', 'pred_category', 'pred_location', 'pred_reason']]
for column in ['category', 'pred_category']:
results[column] = results[column].astype('category')
df.to_pickle('./df.pickle')
tags.to_pickle('./tags.pickle')
results.to_pickle('./results.pickle')
results.groupby('category', observed=True).pred_sentiment.mean().to_frame()
| pred_sentiment | |
|---|---|
| category | |
| business | -0.354167 |
| entertainment | 0.460000 |
| general | -0.412054 |
| health | -0.600000 |
| politics | -0.525424 |
| science | 0.500000 |
| technology | 0.363636 |
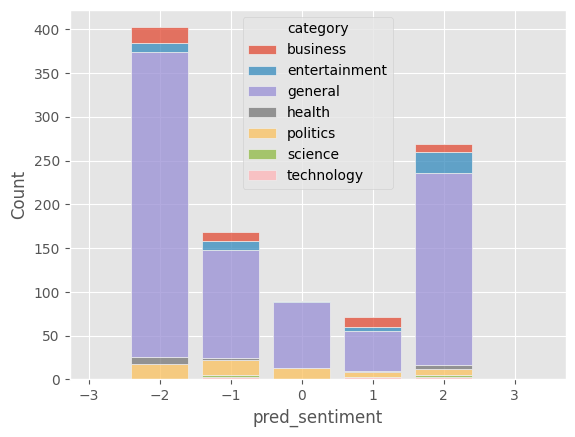
Finally we plot the results. Not unsurprisingly, most news are either very negative or very positive, as they are ‘catchier’ than neutral (i.e., informative but not emotionally binding) news. In this sample of news there is a small skew towards negative sentiment. Given the small amount of text most of the news are classified as “general”. We would need to provide the article to obtain more realistic results, yet it is impressible how much can be achieved with so little content!
import seaborn as sns
sns.histplot(results, x="pred_sentiment", hue="category", multiple="stack",
bins=[-3, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5], shrink=0.8)
<Axes: xlabel='pred_sentiment', ylabel='Count'>